
Explaining The Ring Deployment Model: Safer Releases, Ring by Ring

The principle of ring deployments is simple: rather than releasing a software update to your entire user base at once, you roll it out in stages—each stage a broader ring than the last, and each one acting as a validation gate before the next opens.
The deployment process is one of the highest-risk moments in software development, so it’s no surprise that engineers prefer a bad release that hits 2% of users over one that hits every user simultaneously. One is a controlled test; the other is a fire.
Ring deployment is one way to maintain control.
This article covers what the ring deployment model is, how it compares to related strategies like canary releases and blue-green deployments, and—critically—why feature flags are the most practical way to put a ring deployment strategy into action at the application layer.
What is ring deployment?
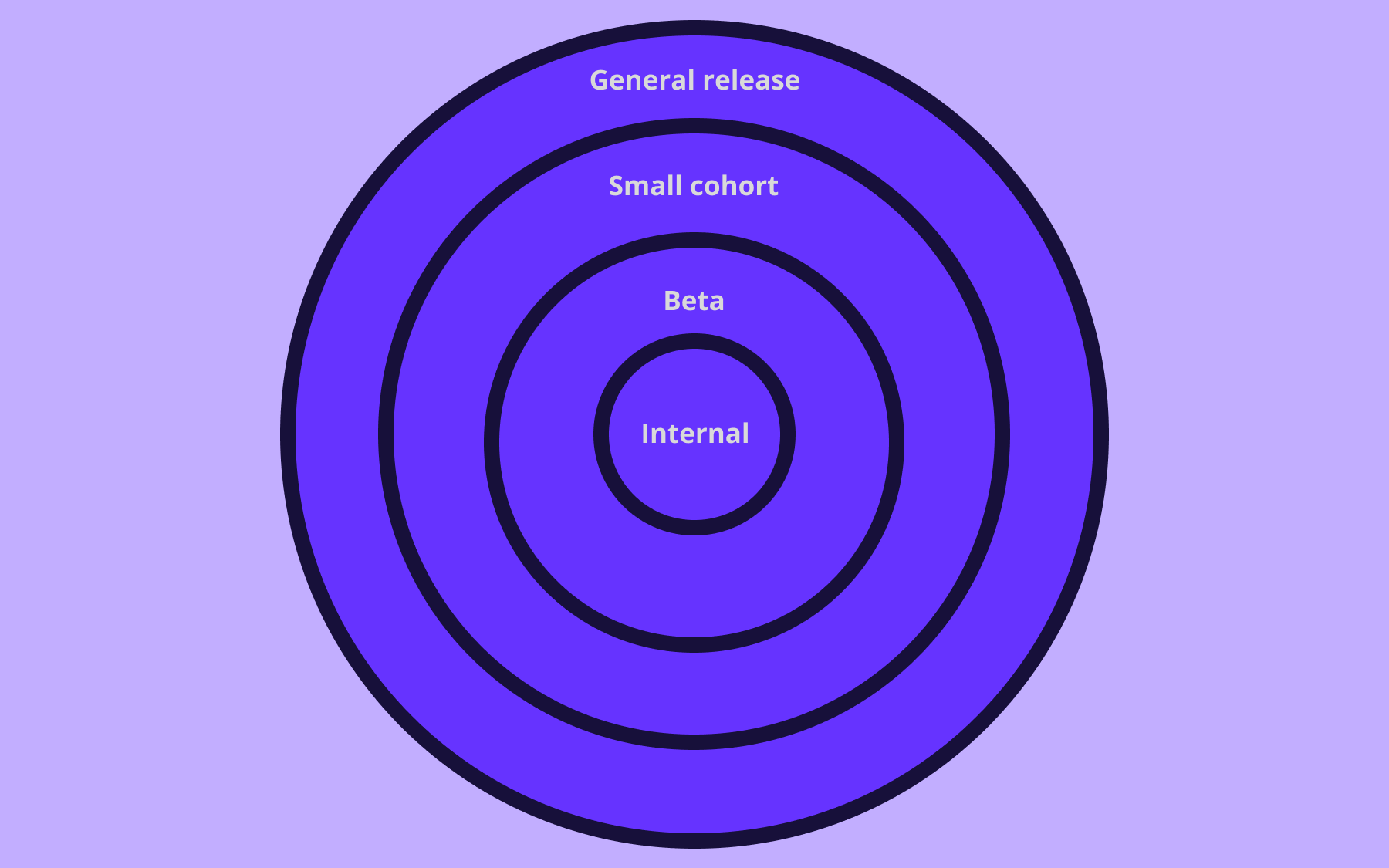
Ring deployment is a staged rollout strategy in which software updates are released to progressively larger groups of users, with each ring serving as a validation gate before deployment continues to the next.
Imagine you’ve thrown a stone into a still pond and the ripples on the surface spread from where the stone dropped in.
Ring deployment refers to concentric rings, each representing a release, expanding outward from a small, controlled core: you validate at each boundary before the circle widens.
The term comes from Microsoft's Windows deployment model, where updates were historically released first to internal teams, then to a wider set of early adopters, and eventually to the general public.
What started as an enterprise IT practice for managing operating system patches has since become a standard pattern in application development, SaaS delivery, and continuous deployment pipelines.
The underlying logic is the same wherever it's applied: prove stability at a small scale before expanding exposure. Each ring represents a checkpoint, not just a percentage.
How rings are typically structured
A common ring structure moves through four stages.
- Internal developers, QA, and security teams that can identify issues before any customer is affected.
- Limited early-access group: Beta users, a specific geography, or a segment of customers who've opted in to test new features.
- A broader but still controlled slice of production traffic, often somewhere between 10% and 50% of the user base, usually a specific cohort of the user base.
- General availability: A full rollout to everyone.
The exact number of rings varies by organisation, and there’s no single correct model.
Some teams run three rings; others run five or six, with each subsequent ring representing a different customer tier or region. What matters is the principle that each ring must prove stable before the next opens.
Why teams use ring deployment
The core appeal of ring deployment, like many deployment strategies, is blast radius reduction.
A release that fails inside ring one affects a small group of users, usually internal. One that slips through to ring two affects early adopters—a group that typically expects some rough edges and is well-placed to provide feedback.
If critical bugs surface at that stage, they stay contained, don't reach most users, and can be addressed early before broader deployment.
Containment is the first benefit, while the second is the quality of signal you get. Staging environments, however thorough, cannot fully replicate production conditions—the traffic patterns, edge cases, and combinations of user behaviour that only appear at scale.
Releasing to a small subset of real users in ring one or two surfaces issues that internal testing misses. An early, real-world signal is more reliable than any pre-production check.
Ring deployment also makes rollback simpler. If ring two shows problems, you halt. You don't need to revert a change that's already hit your entire user base and generated incident tickets.
The blast radius stays small, the necessary adjustments are manageable, and the fix can be deployed progressively before you resume the rollout.
A phased approach gives business and operations teams a natural checkpoint, so they can see the rollout progressing through different rings, review feedback from each stage, and make informed decisions about whether to continue.
That visibility gives stakeholders confidence, especially in regulated industries, where change management processes often require documented evidence of staged validation.
Ring deployment is most valuable when releases are frequent, when a bad deployment has significant customer-facing consequences, or when the user base is large enough that a silent 1% failure represents thousands of affected users.
Ring deployment vs. related rollout strategies
Ring deployment sits within a broader family of progressive delivery techniques. It's worth clarifying where it fits, because the boundaries between these patterns are easy to blur.
Canary releases
A canary release routes a small percentage of production traffic to a new version of a service—say, 1% or 5%—while the rest of your users continue hitting the existing version. It's a powerful technique for catching issues in production with minimal exposure.
The distinction from ring deployment is one of structure. A canary deployment is typically a dynamic traffic split: you dial the percentage up or down based on what you observe, and the target audience is essentially random.
Ring deployment is more deliberate. Rings are predefined cohorts with explicit promotion criteria—an internal team, a group of beta customers, a specific region, all users. Promotion from one ring to the next is a decision, not just a dial adjustment.
The two approaches are complementary.
Many teams run canary-style percentage rollouts within a ring structure: each ring gets a canary before it opens fully to the next. That combination gives you both the structured gating of ring deployment and the fine-grained traffic control of a canary.
Blue-green deployments
Blue-green deployment maintains two identical production environments, blue and green, and switches traffic between them at the infrastructure level.
It's an all-or-nothing cutover: when you flip, the entire user base moves to the new environment at once.
The key strength of blue-green is that rollback is immediate—if the new version has problems, you flip back. However, it's fundamentally a binary switch.
Ring deployment distributes that risk across time and user segments instead, with each ring acting as a smaller, lower-stakes version of the blue-green cutover.
Blue-green is well-suited for infrastructure-level changes; ring deployment is better for feature-level risk management, where you want to observe real user behaviour at progressively larger scales before committing to general availability.
Check out how blue-green compares to rolling deployments in our article.
Percentage rollouts
Percentage rollouts and ring deployment are easy to conflate because both involve releasing to less than 100% of users. The distinction is in who ends up in the target group.
A percentage rollout typically selects users randomly—you pick 10%, and that slice happens to include a random cross-section of your user base. A ring is a defined, intentional cohort. You know who's in it: it might be your internal team, your beta customers, or users in a specific region.
That intentionality is what makes rings carry more signal.
Because you know who is in each ring, you can interpret their feedback more accurately. If your ring two is beta users who are technically proficient, the issues they encounter will be different from those that surface when ring three opens to a broader, less technical audience. Random percentage rollouts don't necessarily give you that interpretive layer.
Here's a simple comparison table of the types of deployment mentioned above and how ring deployment compares:
Feature flags as the mechanism for ring deployment
Ring deployment is a strategy, not a tool. Implementing it requires a mechanism—something that controls which users see which version of a feature at any given moment. Feature flags are the most practical way to do that at the application layer.
Without flags, ring logic usually requires separate deployment pipelines, environment branching, or infrastructure-level traffic routing.
All of those approaches add complexity: they mean ring promotion involves a deployment event, which carries its own risk, and ring membership is often tied to infrastructure config rather than user attributes.
With feature flags, ring membership becomes a targeting rule. You wrap the new feature or change in a flag, define your rings as targeting segments, and enable the flag for ring one only.
Everyone else continues to see the existing behaviour. Promotion to ring two is a configuration change, meaning you update the segment rule, not a redeployment. Rollback is equally instant: toggle the flag off and all rings immediately revert, without touching the underlying code.
That operational simplicity has several practical advantages:
- Rings can be defined by user attributes—account type, region, subscription tier, beta opt-in status—rather than by infrastructure config
- Ring membership reflects who users actually are, not where their requests happen to be routed
- Promotion is visible and auditable in one place; the flag's change history is a record of every ring transition
- Because the feature code is already deployed to all environments, the act of opening a ring to subsequent rings carries no deployment risk, only the flag state changes
How to implement a ring deployment strategy with Flagsmith
In practice, implementing ring deployment with Flagsmith is a sequential process built around segments and feature flags.
1. Define your rings as segments
In Flagsmith, a segment is a group of users defined by rules—an attribute value, an identifier, a percentage.
Your first ring might be an internal segment containing your own team's user IDs. Your second ring might be users who have the beta_access attribute set to true. Your third ring might be a percentage-based rule covering 20% of production traffic. Your fourth is a full rollout, when the flag is enabled for everyone.
2. Wrap the new feature in a feature flag
Enable the flag for ring one only and monitor. Watch error rates, latency, and user feedback.
When ring one is stable, promote to ring two by updating the segment rule. Repeat the monitoring step.
When ring two clears, open to ring three, and so on until you reach general availability at 100%.
Flagsmith supports percentage rollouts, identity targeting, segment targeting, and environment-based flags—all of which map naturally onto ring logic, depending on how a team has defined its rings.
The entire process—ring definition, promotion, and rollback—happens in the Flagsmith interface, not in your deployment pipeline. The person managing the ring rollout doesn't need to touch infrastructure or trigger a release.
A product manager or engineering lead can promote between rings by updating a flag, and rollback, if it's needed, takes seconds.
Conclusion
Ring deployment is one of the most reliable structural responses to release risk in software development. By releasing to progressively larger groups of users, each ring a validation gate before the next, teams contain the blast radius of bad releases, gather feedback from real users at manageable scale, and give operations and business stakeholders a natural checkpoint throughout the rollout.
Feature flags are what make this practical at the application layer. They let you define ring membership by user attributes rather than infrastructure state, promote between rings through configuration rather than deployment, and roll back instantly if something goes wrong.
The ring deployment strategy and feature flags are, in practice, designed for each other.
If you want to start shipping with a structured approach to release risk, Flagsmith gives you the segments, targeting rules, and flag management to implement a ring deployment model from day one.
Ring deployment FAQs
What is a ring deployment model?
A ring deployment model is a structured approach to releasing software updates in which changes are deployed progressively to different user groups—or rings—starting with a small internal group and expanding to the full user base. Each ring acts as a validation gate: the update only moves to the next ring once the current one has proven stable.
How many rings should a ring deployment strategy have?
There is no fixed number. Most teams use three to five rings, but the right number depends on the size of the user base, the frequency of releases, and the risk profile of each change.
What matters is that each ring represents a meaningfully different cohort and that promotion criteria are defined before the rollout begins.
Can ring deployment be used for infrastructure changes as well as application features?
It can, though the mechanism differs.
Infrastructure-level ring deployment typically requires traffic-routing controls—load balancer rules, service mesh configuration, or platform-level traffic-splitting tools. Feature flag-based ring deployment operates at the application layer and is best suited to feature-level changes.
For infrastructure changes, teams often combine both approaches: feature flags for the application logic and infrastructure-level controls for the underlying services.
























OpenTelemetry, without the vendor lock-in: Introducing full observability for Open Source and Self-Hosted Flagsmith customers




































































.png)
.png)

.png)

.png)



.png)















.webp)