
What Is Trunk-Based Development? A Complete Guide


Long-lived feature branches can look like a safe way to organise software development, but they often create trouble later.
The longer code sits in isolation, the more likely it is to drift away from the main codebase, which leads to integration issues, painful merge conflicts, slower feedback, and release anxiety when it is finally time to merge code and deploy.
Trunk-based development is the branching strategy many high-performing development teams use to avoid that pattern. Instead of letting developers work in separate branches for days or weeks, trunk-based development enables code integration to happen continuously.
Developers commit small changes to a shared main branch, keep the build green, and treat the code base as something that should stay production-ready.
In this guide, we’ll cover what trunk-based development is, how it works with CI/CD, the main benefits, the common pitfalls, and why feature flags help teams practise it safely.
What is trunk-based development?
Trunk-based development is a branching strategy where all developers commit small, incremental code changes to a single shared branch, usually called trunk, main, or mainline, at least once a day. Instead of building features in isolation for long periods, developers integrate frequently into a single main trunk.
In practical terms, the best trunk-based development definition is breaking work into the smallest useful unit and delivering code in short steps. Rather than waiting until a feature is completely finalised, developers commit progress continuously so the main codebase stays current and integration problems stay small.
That does not mean branches disappear completely.
Teams can still use short-lived branches where needed, but they should last only a few hours or, at most, a day or two. The key rule is that no branch should live long enough to diverge meaningfully from the trunk branch. Once a feature branch becomes a long-lived feature branch, the team reintroduces the same problems that trunk-based development is meant to solve.
Here’s a simple visualisation of what the trunk-based development workflow looks like.
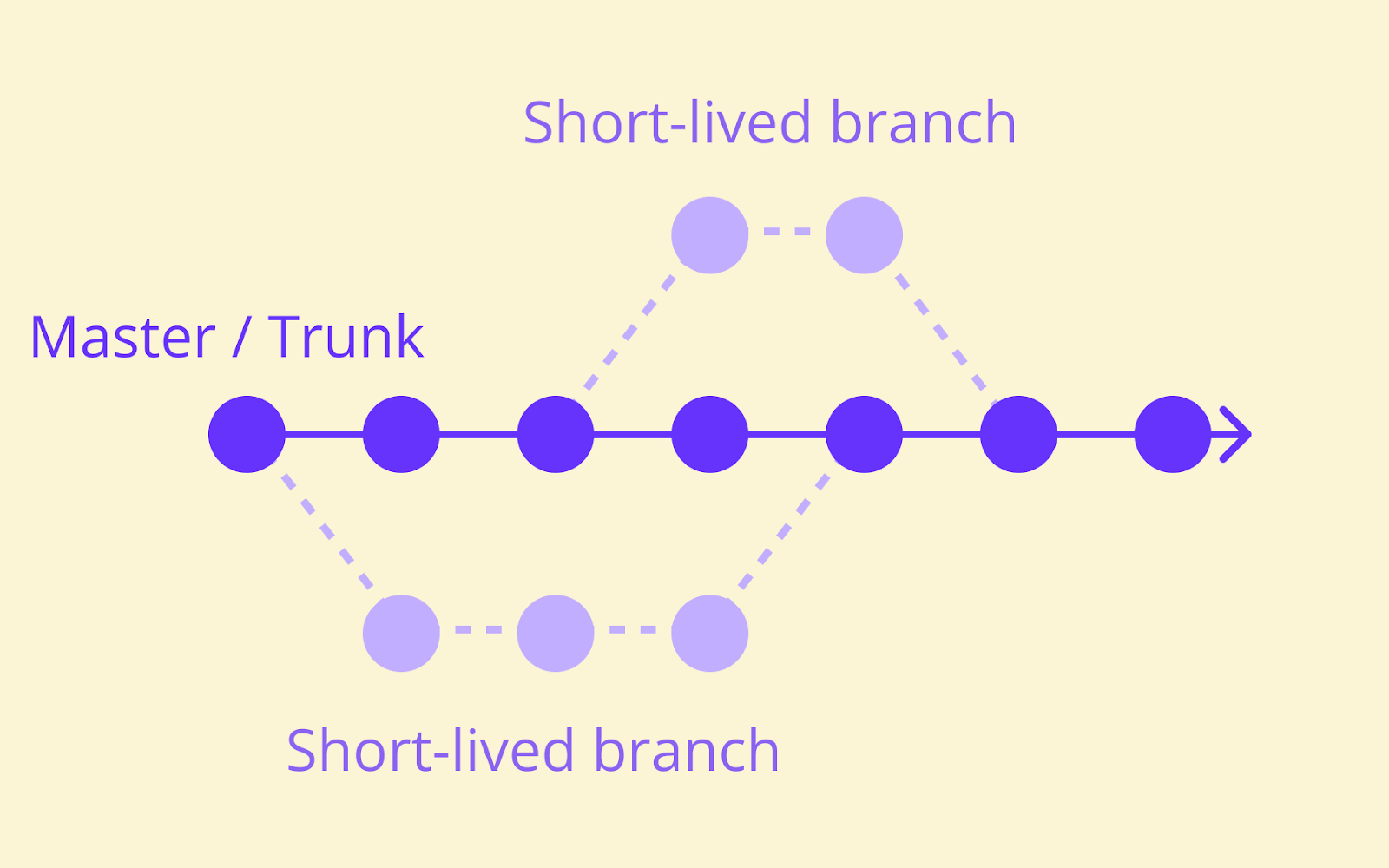
Branch lifespan is the main factor that makes trunk-based development different from feature-based development or Gitflow.
In those branching models, developers create separate branches for features, release branch work, and hotfixes. Over time, those separate branches create more branches, more coordination overhead, and larger merge branches to reconcile.
The key factor is that Gitflow can lead to code freezes, release hardening phases, and the kind of merge challenges that slow down software delivery.
Here’s a visualisation of the Gitflow process.
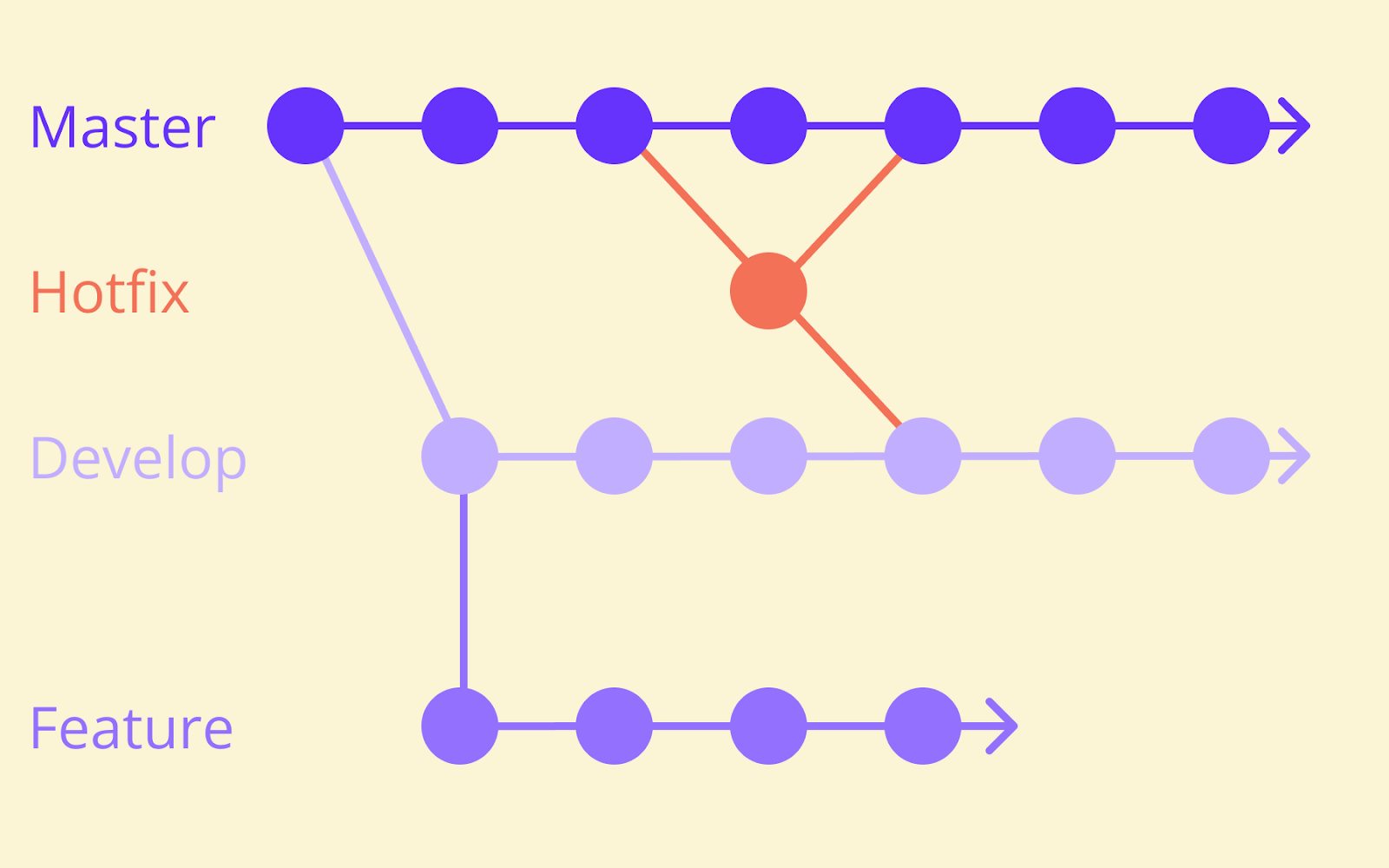
That contrast between trunk-based development vs. Gitflow is what drives home its value. The next question is how the development process works in practice.
How trunk-based development works
When used on a daily basis, trunk-based development is less about a specific Git command and more about a working rhythm.
Developers work in small batches, and each commit should represent a meaningful but limited unit of progress. That could be a refactor, a new API endpoint, a backwards-compatible schema change, a test, or a partial UI change hidden from users.
Because the batches are small, developers commit frequently. Some teams commit directly to the main branch. Others use short-lived feature branches and merge code back quickly through lightweight pull requests.
Either way, the rule is the same: daily merges into the single main branch are normal, and long delays are not.
That rhythm only works if the trunk stays healthy. In trunk-based development, the build must stay green. If a commit breaks the main branch, the team fixes it immediately or reverts it. The shared branch is not just another branch in source control. It is the team’s shared reality, and protecting it is part of the development process.
Automated testing is what makes that possible. Developers run unit tests and relevant integration tests before they push. Every commit to trunk triggers automated testing in CI. Fast feedback is essential because trunk-based development depends on finding problems early, while the code changes are still small and easy to understand.
Some teams still use a release branch when necessary, especially for hotfixes or controlled production releases, but in trunk-based development, a release branch is a short-term snapshot of trunk, not a separate stream of ongoing development. Any bug fixes made there should be merged back to the trunk promptly so the main codebase stays up to date. For teams with very high deployment frequency, release branches often become unnecessary.
Trunk-based development and CI/CD
Trunk-based development is not just compatible with continuous integration. It is the branching strategy that makes true continuous integration possible.
If code is being developed in multiple long-lived branches, integration is delayed by design. That is not continuous integration; it’s deferred integration.
In a trunk-based workflow, every change merged to the main branch triggers the CI pipeline automatically. Unit tests, integration tests, and other checks run on every commit. Because developers commit often and each code change is small, problems are easier to isolate and fix. Instead of debugging weeks of drift between separate branches, the team only needs to inspect a small difference.
Continuous integration keeps the main codebase healthy, and a consistently green trunk makes continuous delivery possible. If the main branch is always in a deployable state, teams can deliver software whenever the business needs them to—that’s the real foundation of continuous delivery and continuous deployment.
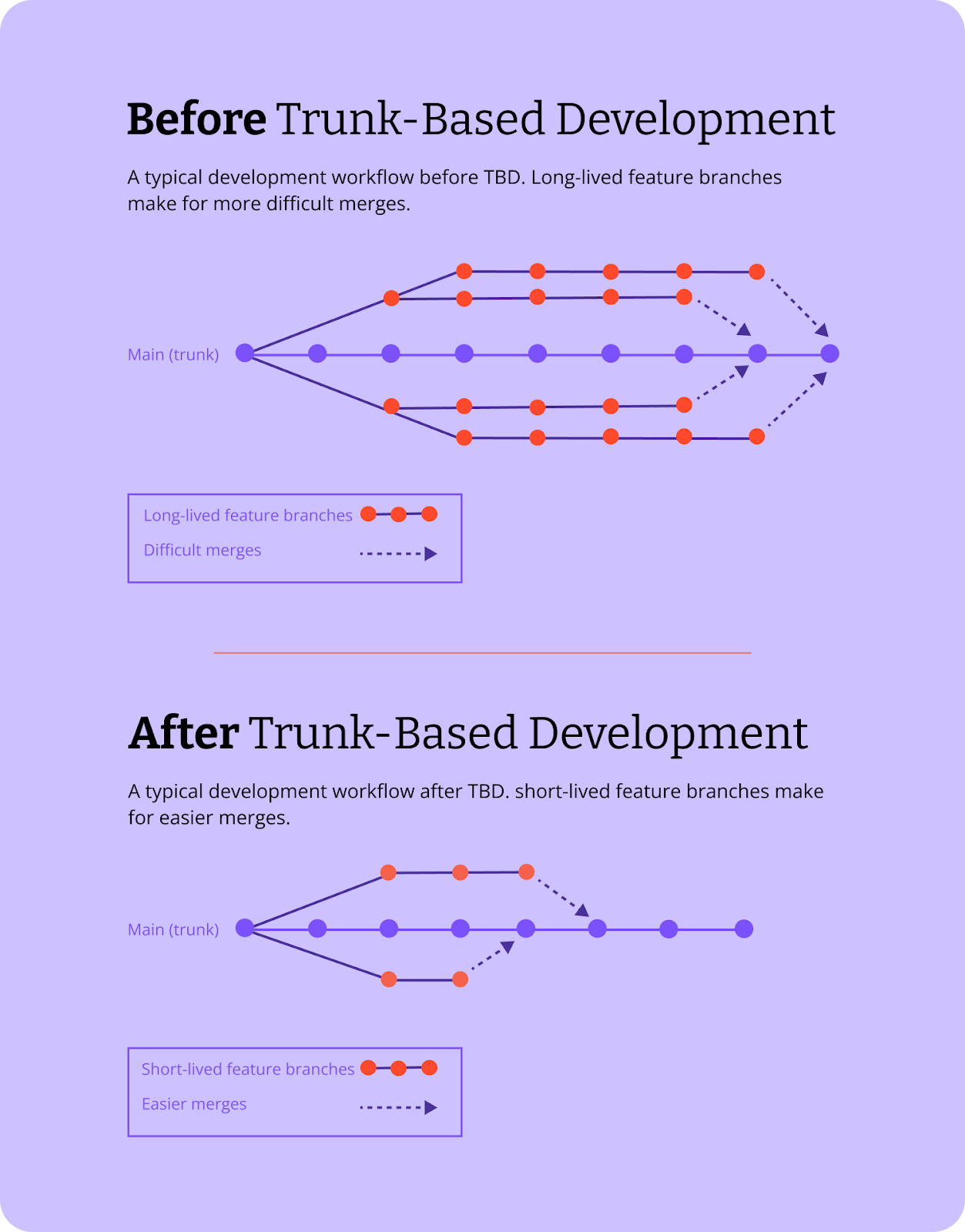
Long-lived branches break that feedback loop.
A developer may think they are making safe progress in isolation, but by the time they merge code, other developers have already changed the main codebase.
The results are:
- Slower code integration
- More merge conflicts
- More brittle pull requests
- More uncertainty about whether the final code will work in the production environment
AI-assisted development has further highlighted this bottleneck as it can increase the volume of code changes moving through a system.
According to DORA’s 2025 State of AI-assisted Software Development report, AI adoption now improves software delivery throughput, but it still increases delivery instability.
“While teams are adapting for speed, their underlying systems have not yet evolved to safely manage AI-accelerated development.”
– DORA State of AI-assisted Software Development 2025
Faster code creation needs strong foundations underneath it. Trunk-based development provides those foundations through short feedback loops, strong version control practices, and working in small batches.
There’s still an obvious tension: If developers commit incomplete work to the trunk all the time, how do they avoid exposing unfinished features in production releases?
Benefits of trunk-based development
Fewer merge conflicts
Small, frequent merges are easier to resolve than large, infrequent ones.
When a feature branch lives for weeks, it diverges from the main branch in dozens of places. When short-lived feature branches merge back the same day, the differences are smaller and easier to reason about.
Faster feedback
Because developers commit early and often, build failures, test failures, and integration issues show up quickly. This speed improves code quality because the person who made the change can still understand the context more easily.
It also helps code review: Reviewers can focus on smaller pull requests instead of trying to interpret a huge backlog of new code all at once.
Continuous deployability
Trunk-based development helps teams keep the main codebase in a releasable state. Development teams don’t need to wait for big stabilisation windows or special release cadences and can deliver software in incremental updates, aligning production releases with business needs, rather than with branch management overhead.
Risk reduction
Smaller code changes mean a smaller blast radius.
If something goes wrong in the production environment, it’s easier to identify which commit introduced the issue. Rollbacks are simpler, bug fixes are faster, and it’s easier to improve code quality over time because the team’s not dealing with multiple versions of reality across multiple branches.
Collaboration
When developers work on a shared trunk branch, everyone stays closer to the same main codebase, which improves visibility, keeps other developers informed, and reduces the chance that separate branches become disconnected from each other.
Instead of working in parallel silos, the dev team shares a single evolving code base.
Releasing more frequently tends to improve stability rather than hurt it. Each deployment carries fewer changes, so there’s less uncertainty in each release.
However, those benefits still require work to realise, which is why teams often stumble over the same adoption problems.
Common pitfalls
Not adjusting the code review process
One of the biggest pitfalls is keeping a heavyweight code review process while trying to implement trunk-based development.
If code review takes too long, small commits stop feeling worthwhile. Developers wait, pull requests grow, branches stay open longer, and the team ends up back in a long-lived branches model under a different name.
Asynchronous review
Asynchronous reviews can create the same problem. If a developer opens a PR and waits a day or two for comments, the branch is already drifting away from trunk.
Teams often get better results from lightweight reviews, synchronous collaboration, or pair programming, because those approaches keep feedback loops short and daily merges realistic.
Underinvestment in automation
Another common mistake is not investing enough in automated testing.
Trunk-based development depends on trust in the pipeline. If automated testing is slow, flaky, or incomplete, developers become hesitant to merge code. Once the trunk branch is no longer reliable, people retreat into separate branches to feel safe, and the branching strategy starts to collapse.
Not breaking the habit
Teams also underestimate the habit change involved in small batches. Trunk-based development is not just a tooling change in a version control system. It requires developers to think differently about how they break down work.
Instead of building an entire feature behind one long PR, they need to think in small shippable slices, backwards-compatible changes, and incremental updates.
Merging incomplete features incorrectly
The final pitfall is merging incomplete features into the production environment without a way to hide them. This practical gap makes many teams nervous about trunk-based development. The whole system depends on frequent code integration, but not every feature is ready to be visible when the code lands. At this point, feature flags become essential rather than optional.
Once you see that tension clearly, the fit between feature flags and trunk-based development becomes obvious.
For quick reference, here are the main benefits and common pitfalls again:
Feature flags and trunk-based development
Trunk-based development requires developers to commit to the trunk constantly, but product teams often don’t want every feature exposed the moment the code is merged. Feature flags solve that problem by decoupling deployment from release.
With feature flags as part of the trunk-based development process, incomplete features can be merged to the main branch safely while staying hidden from end users. That means developers commit frequently, CI/CD pipelines keep flowing, and the trunk stays green without forcing unfinished work into public view.
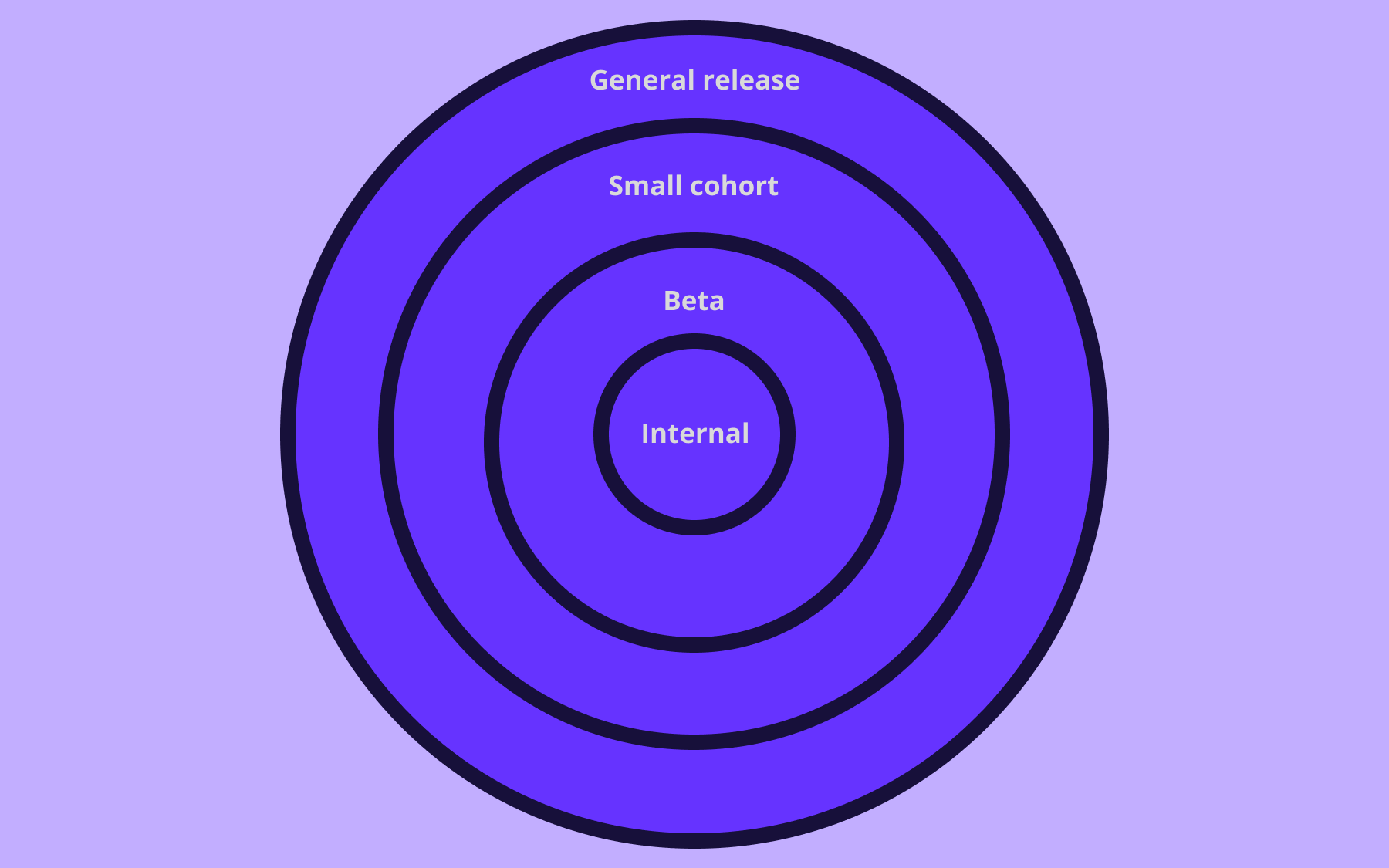
Feature flags also let teams test safely in the production environment.
A flag can be turned on for a developer, a QA team, or an internal cohort before a wider rollout, making it easier to validate new features, reduce risk, and improve code quality without blocking the development process.
Feature flags also provide an operational safety net. If something goes wrong after release, the team can disable the feature immediately instead of creating an emergency branch or rushing a hotfix deployment. Feature flags don’t just enable trunk-based development; they make it safer and easier to sustain.
Flagsmith gives development teams a straightforward way to enable trunk-based development in real production workflows by separating merge timing from release timing. Get started with Flagsmith for free to start benefitting from feature management and improved deployment processes.
Start shipping with confidence
Trunk-based development is the branching strategy that underpins high-performing engineering teams by reducing the cost of code integration. Instead of letting developers work for long periods in separate branches, it keeps everyone close to a single main branch, encourages small batches, and makes software delivery more predictable.
Trunk-based development works with CI/CD because it’s the foundation that continuous integration depends on. Frequent commits, automated testing, fast feedback loops, and a production-ready main codebase make continuous delivery practical rather than aspirational.
However, there is one more ingredient that makes the model work smoothly in real organisations: a way to decouple deployment from release. That’s the role of feature flags. They allow development teams to keep the trunk moving, ship new code safely, test in production, and release new features only when they are ready.
If your team wants to commit to trunk every day without increasing release anxiety, Flagsmith gives you the control layer that makes that possible. Trunk-based development gives you the flow. Feature flags give you the safety. Together, they help teams ship with confidence. Contact us to learn how Flagsmith can help your team.

























OpenTelemetry, without the vendor lock-in: Introducing full observability for Open Source and Self-Hosted Flagsmith customers




































































.png)
.png)

.png)

.png)



.png)












.webp)