
Progressive Delivery for Building LLM-Powered Features


Everyone's adding AI-powered features to their products, but many product teams are realising that building the MVP of these features is the easy part. A smart engineer can throw together a really impressive proof-of-concept in a few days, and a product team can polish that demo into a ready-to-launch feature in perhaps a few weeks.
It's the next part—continuing to improve AI performance after that initial launch—where the pain starts. Generative AI is an unintuitive, jagged intelligence. A change that improves how the AI handles certain types of problematic input can introduce unintended issues in other types of input which had been working fine previously. Teams can end up chasing their tails, constantly adjusting prompts and experimenting with new models or context management techniques without making much forward progress on overall performance.
If you're not testing these incremental changes in a systematic way, you're at risk of falling into this game of whack-a-mole. Manual "vibe check" testing, where you test a change against a small set of sample inputs, isn't sustainable.
When you take a step back, this shouldn't be a surprise—we've known for a long time that relying entirely on manual tests to verify software is a bad plan. A suite of automated tests provides a much more robust protection against regressions. Likewise, we've learned that Progressive Delivery—rolling out new features in a controlled way and using experimentation to validate the impact of each change—allows teams to safely increase the pace of software delivery.
We can apply Progressive Delivery to AI-powered product features too: in this article you'll learn how, using feature flags and AI evals.
Progressive Delivery: moving fast with safety
Progressive Delivery is a set of engineering and product management techniques which allow teams to safely accelerate the pace at which they deliver value to users. It builds on the concepts of Continuous Delivery, layering on product experimentation. Continuous Delivery is all about keeping your software in a continuously releasable state. Progressive Delivery adds in the idea of incremental releases using feature flags, along with a feedback loop of technical- and business-focused metrics which allow us to measure the impact of each change.
For example, let's imagine we're an insurance provider and we want to improve our onboarding experience with a smart address form. Rather than forcing users to type street name, city, state, zip code, and so on, we will provide them with a free-form text box and use a 3rd party library to automatically figure out the full address.
BEFORE

AFTER
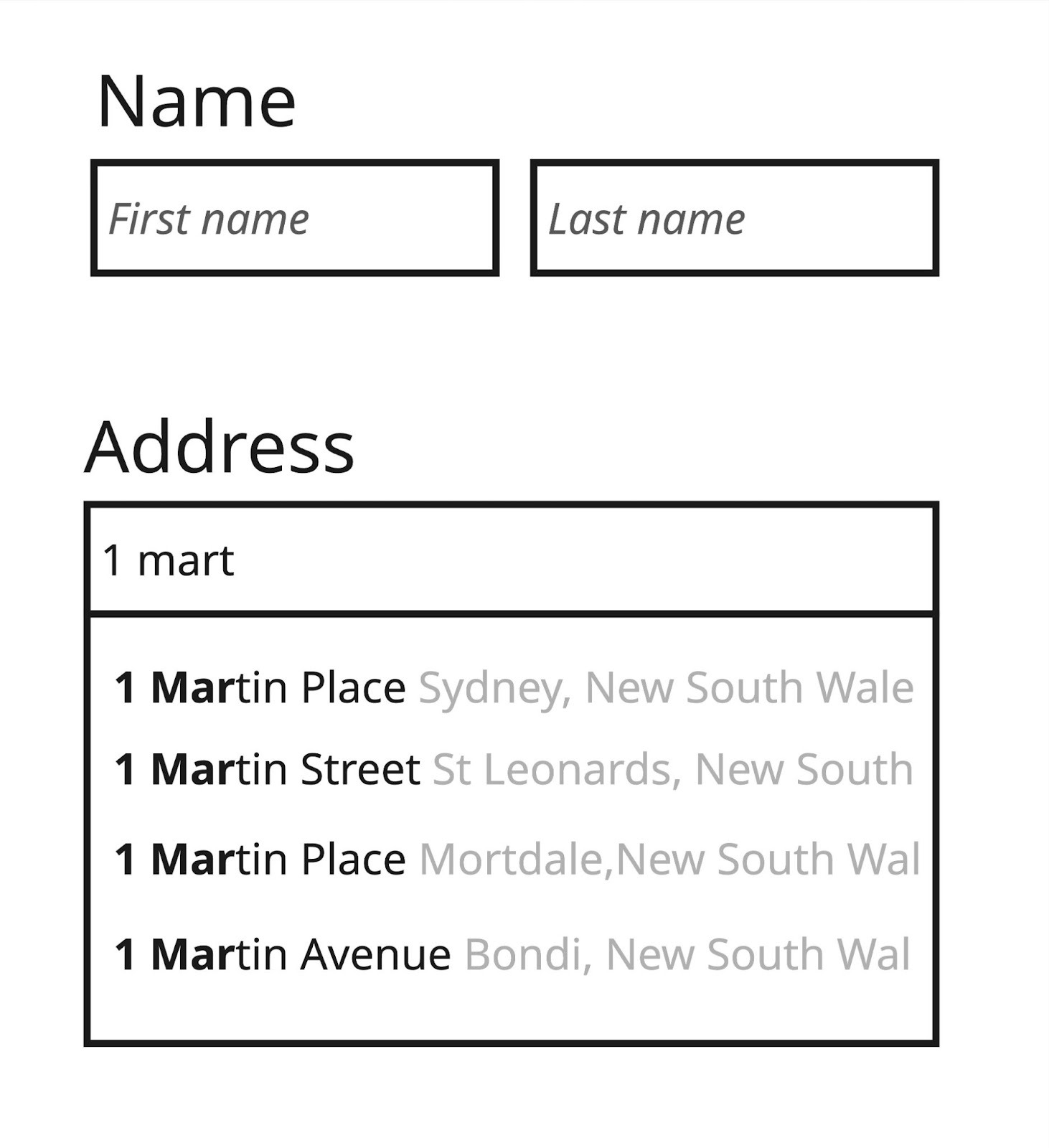
To roll out this change using Progressive Delivery techniques, we would introduce a feature flag which controls whether a user sees the existing manual form or the new automatic form. When the shipping address form is being displayed, our code would check the feature flag and render the appropriate UI component.
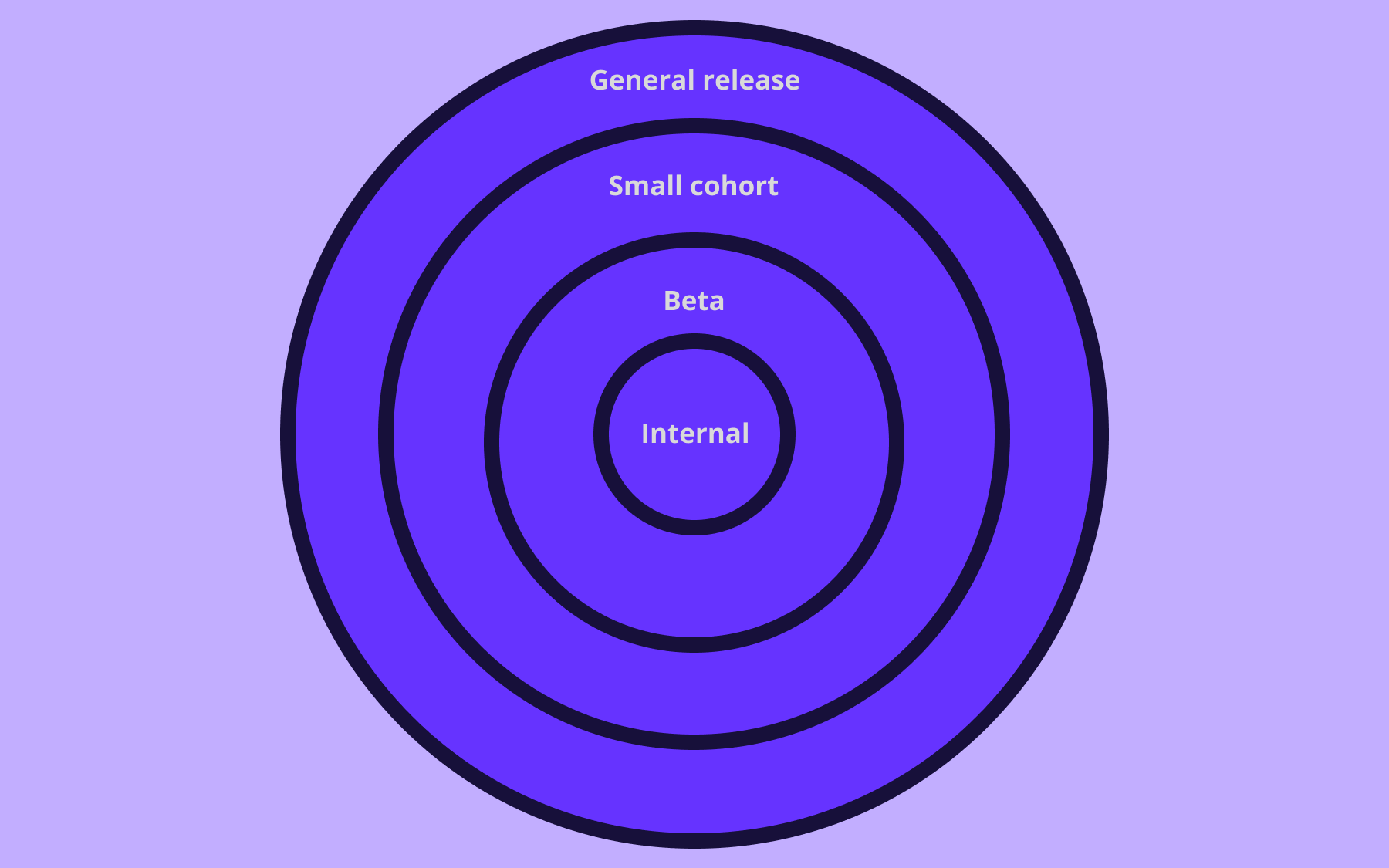
We'd deploy the code change to production but initially configure that feature flag to be off for all users. When we're ready to roll out this new feature, we'd first test it internally by turning the feature on in production but only for internal users. Assuming we didn't find any issues, our next step would be a canary release, turning the feature on for 5% of our user-base. Next we'd move on to an A/B test, turning on the feature for 50% of our users so we could measure how the new experience performs side-by-side with the old one. Once our A/B test concludes successfully, we would complete the rollout, turning the feature flag to 100%. Soon after, we would retire the feature flag and remove it from our codebase.
At each stage during this rollout, we'd be watching our technical metrics (error rates, page load time, etc) as well as business metrics (onboarding conversion rate, for example). If we notice an issue, we can immediately turn the feature flag off. This safety net gives teams the courage to make changes at a faster pace, knowing that issues can be detected and remediated quickly.
Progressive Delivery for AI
Now let's see how we can apply these ideas to a change in an AI-powered feature. We're now working on a retail banking app. We've recently added a feature that allows the user to ask questions about their transaction history and get answers in real time, via an LLM.
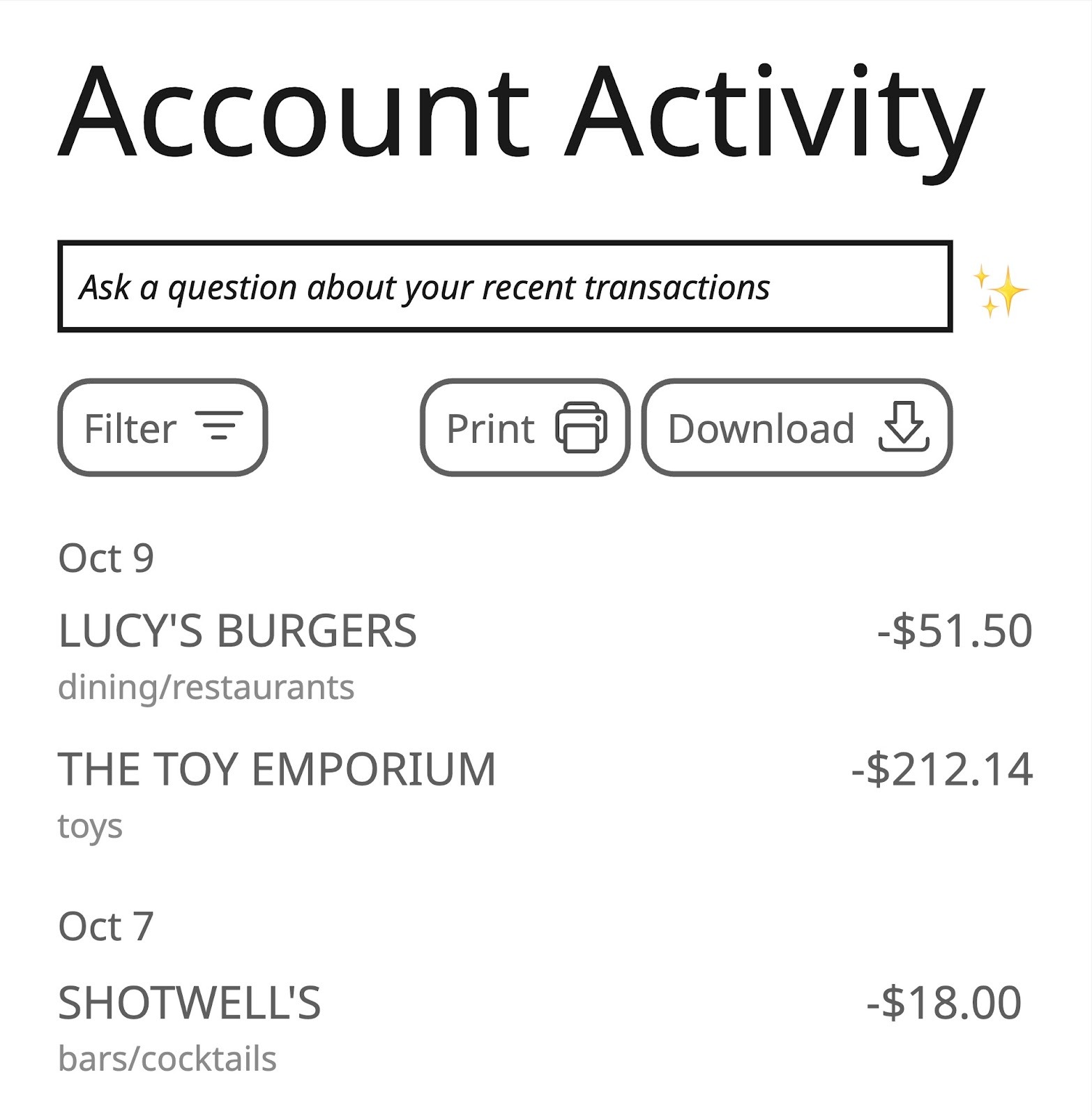
We've noticed the AI's answers can be overly verbose at times, so we're going to tweak the prompt that powers this feature to try and encourage the LLM to be more succinct (changes in parentheses):
UPDATED PROMPT
You are an assistant at a bank who helps customers answer questions about their transaction history. I've included the user's transaction history and their question below.
(Be sure to answer the question succinctly; use no more than 5 sentences.)
<transactions>
{transaction_history}
</transactions>
<user_question>
{user_question}
</user_question>
We can choose to use Progressive Delivery techniques for this prompt change, similar to any other code change. We'll deploy both the old and the new version of the prompt, and use a feature flag to control which version of the prompt is used to answer a given question. We can then measure the impact of the change by checking our product analytics.
Choosing a prompt via a feature flag
There are a few different ways we can control which prompt is used via a feature flag.
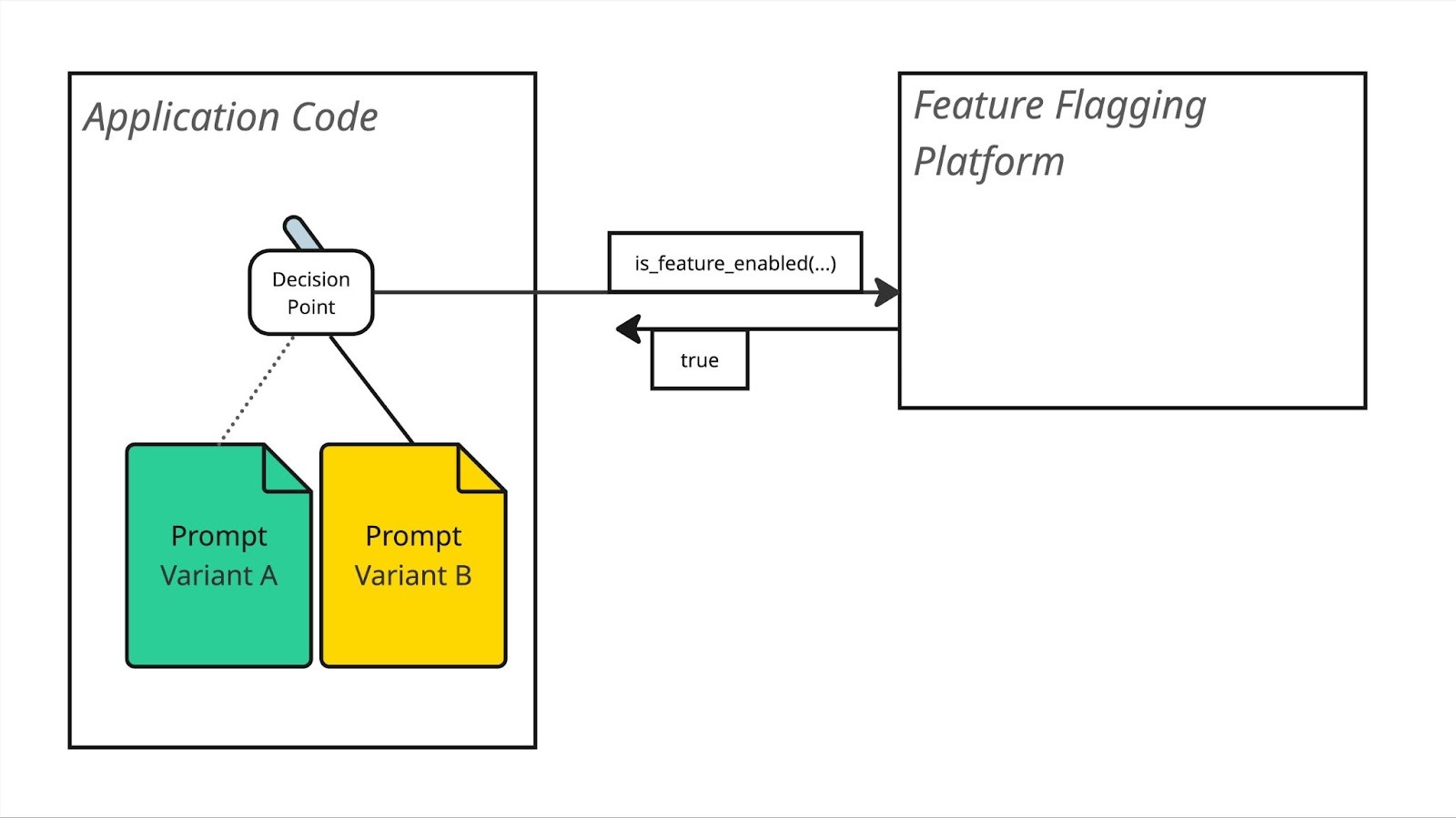
If your prompt templates are deployed as hardcoded strings alongside your code then you can simply ship both versions of the prompt as hardcoded constants, and choose which one to use based on a boolean flag:
if feature_flags.is_feature_enabled("use_succinct_prompt_for_transactions_query"):
prompt_template = SUCCINCT_TRANSACTIONS_QUERY_PROMPT
else:
prompt_template = ORIGINAL_TRANSACTIONS_QUERY_PROMPT
# … use prompt_template to send the question to LLM …
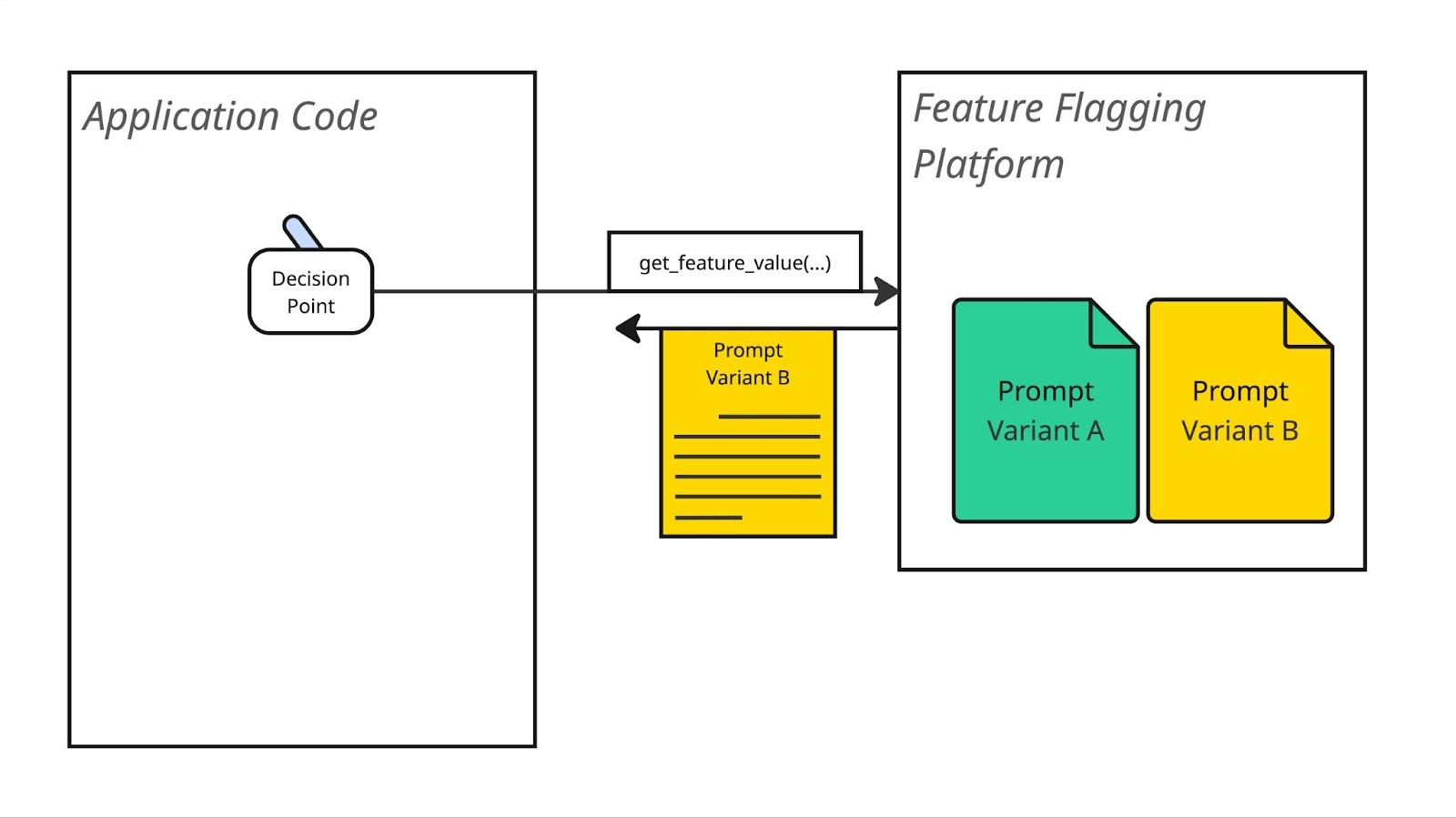
You could also manage the actual prompt template within your feature flag management platform by creating a string feature flag with different variants of the flag containing the different prompts:
prompt_template = feature_flags.get_feature_value("transactions_query_prompt")
# … use prompt_template to send the question to LLM …
This second option may be tempting. It opens up the possibility for you to iterate on these prompts without even needing a code deploy—you can simply update the feature flag variants in your flag management platform and they'll be live instantly! However, this is also a pretty risky approach, even with A/B testing in place. You're basically live-coding in production, leaving version control behind and bypassing the quality checks of your continuous delivery pipeline.
A middle ground approach is to use a dedicated prompt management platform (langfuse, braintrust, arize, amongst others) to store your prompts, and use your feature flag management platform to choose which prompt ID or version ID to use:
prompt_version = feature_flags.get_feature_value("transactions_query_prompt_version")
prompt_template = prompt_store.get_prompt("transactions_query", version=prompt_version)
# … use prompt_template to send the question to LLM …
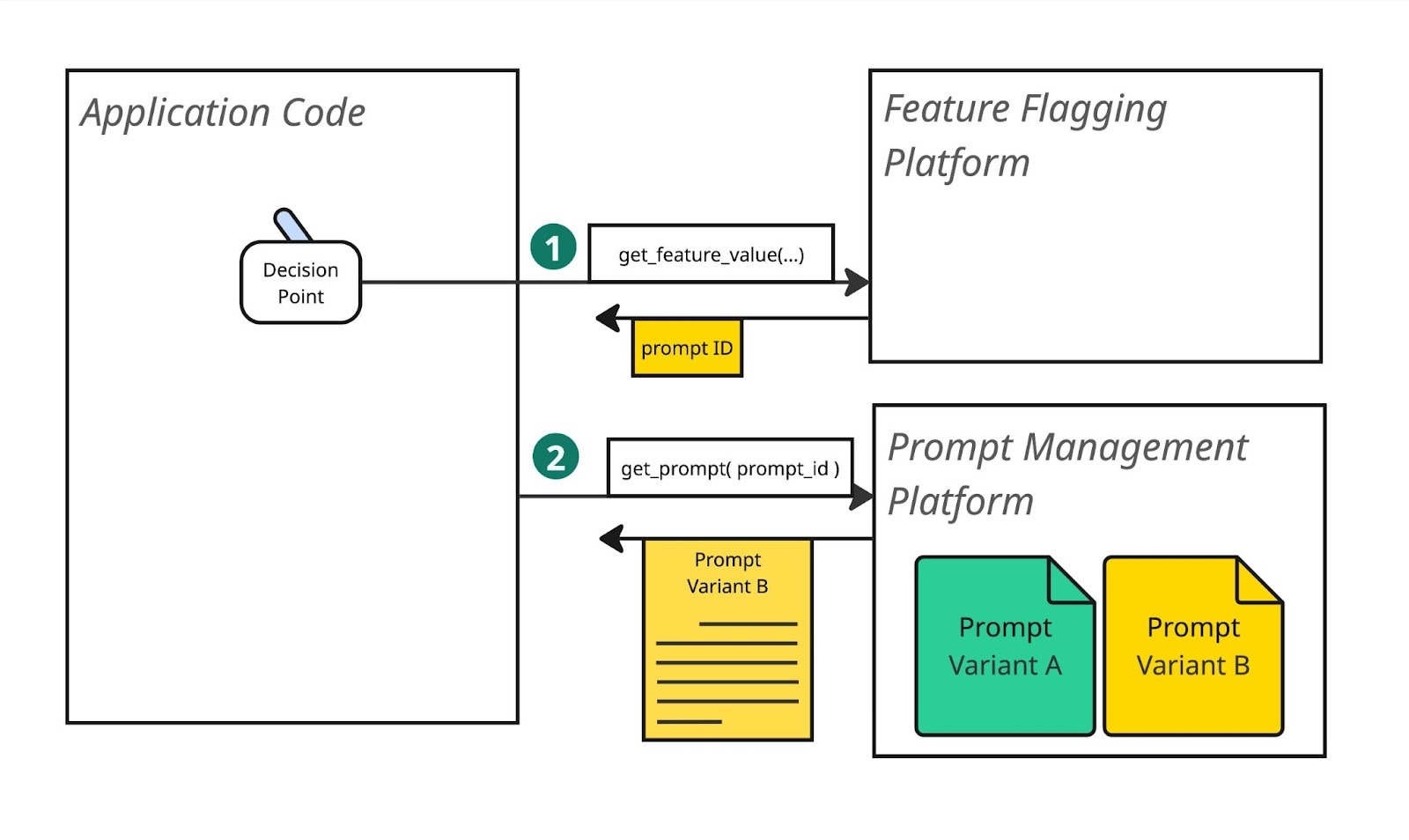
Measuring the impact of a prompt change
Whatever approach we use, with a feature flag decision point in place we are ready to perform a progressive rollout of the new prompt. Just like our smart address form, we can start with a canary release, configuring our feature flag platform so that 5% of transaction queries use our new prompt. If things look good, we can ramp up to a 50% A/B test and let that experiment sit for a while. Again, if things look good, we would ramp to 100% and then shortly after we'd remove our flag and clear out the old version of the prompt.
There's an important question here though: how exactly do we measure the impact of this change? How do we know if "things look good"? We have a few options:
Traditional metrics
We can look at whether the new prompt has any effect on our existing product metrics: are people more likely to ask multiple questions when using the new prompt, for example. We can also check on technical metrics: does the new prompt affect how quickly we're able to retrieve an answer from the LLM, or perhaps how many tokens we're spending.
User feedback metrics
We could explicitly ask our users for feedback on the LLM's response: "was this answer helpful?".
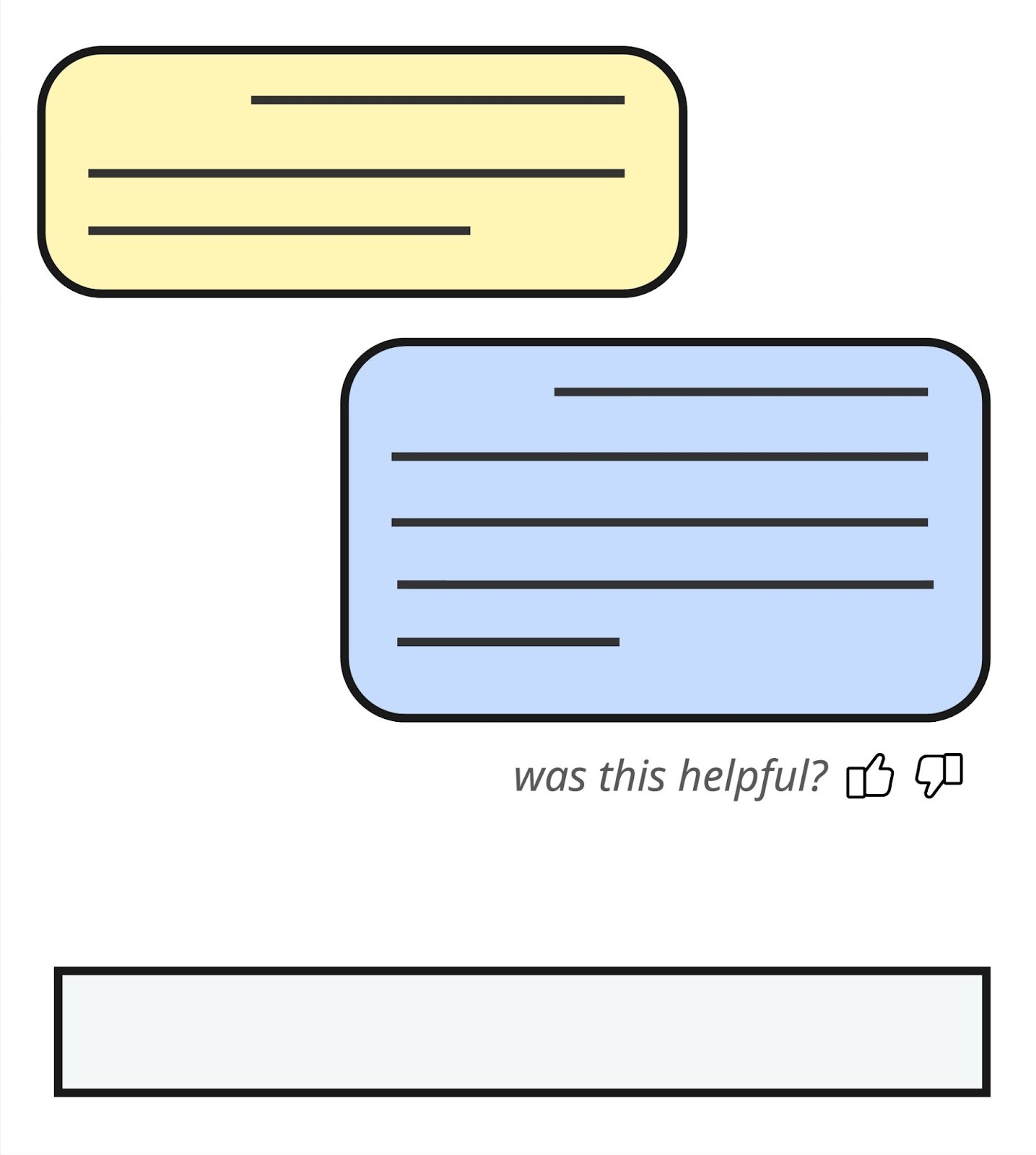
You've probably noticed this pattern yourself in AI-powered product features—it's a simple way to get focused feedback on an LLM's performance, with the caveat that you're likely to only get feedback from users who feel strongly, one way or the other.
Evals
A third option for measuring the impact of this prompt change is via AI evals— purpose-built instrumentation that specifically measures the performance of your LLMs. AI evals are an important topic that's well worth deeper study (Hamel Hussein's writing is a particularly great resource), but to give a quick sense of what they look like, here are some example evals we might look at for our product questions feature:
- How many characters are in the LLM's response? This happens to be exactly the metric we're trying to move with this change!
- Does the response answer the user's question? You might wonder how we measure this in an automated way. A common approach is to feed the question and the answer to another LLM and ask it "does this response answer the user's question" (a technique called LLM-as-a-judge). This won't work perfectly, but it will spot responses like "I'm sorry, I'm not able to answer your question based on the information available".
- Does the response contain information that wasn't explicitly provided in the user's transaction history? Another LLM-as-a-Judge eval, this time attempting to spot when the LLM is either hallucinating, or pulling in potentially incorrect information from its training set.
Running these evals against your LLM inputs and output in production will provide additional metrics that you can use to assess your prompt change—both to see if the change had the impact that you intended, and also to detect whether the change had inadvertent effects on other aspects of your AI's performance.
That second part is what makes a good suite of AI evals so valuable—they help prevent the game of whack-a-mole that you can otherwise fall into when making LLM changes. Imagine, for example, that our prompt change did successfully reduce the verbosity of the AI responses but it also made the LLM more likely to respond with "sorry, I'm not sure" in certain circumstances. This sort of unintuitive regression is quite possible when working with the strange alien brain of an LLM, and it can be impossible to spot if you're only testing you change manually - i.e. "vibe checking" - or via automated tests that use a small "golden dataset" of inputs.
Using feature flags to A/B test your LLM changes in production with evals generating a feedback loop provides much more confidence in the impact of a change, which in turn allows you to rapidly iterate towards more magical AI-powered features.
Not just prompts
In our example above we were A/B testing a prompt change. These are a particularly good candidate for progressive delivery, but there are other LLM changes that can also be A/B tested in the same way.
What happens if we switch models?
The AI landscape changes fast. At some point you're going to consider switching to a newer model - or a smaller model, or a larger model. You might even explore switching to a different model provider.
Running different models side-by-side in a canary release or A/B test lets you use evals and product metrics to compare the quality of their responses, while also looking at technical metrics to measure differences in latency and cost.
If you're not comfortable running an experiment in production with your user-base as guinea pigs, you could also perform a Dark Launch - send production traffic to both models and compare the results, but only use the result from your existing model.
Tweaking meta parameters
You can also use an A/B test to look at how model settings like temperature, top-p and top-k affect the quality of responses. For scalar values like these you may even want to run a multivariate test.
Advanced AI engineering
You might be considering creating a custom fine-tuned model, or using a different RAG strategy, or even introducing agentic workflows. All of these changes can (and should) be done in a safer way using the Progressive Delivery techniques we've discussed in this article.
Conclusion
Building AI-powered features can feel like wielding a powerful new form of magic: unpredictable, sometimes jaw-dropping, occasionally maddening. But it turns out that the same Progressive Delivery techniques that have helped engineering teams ship regular old software faster and safer—feature flags, canary releases, A/B testing—apply just as well to this new magic.
Just as with other types of software, the key is a controlled rollout with a clear feedback loop. The controlled rollout uses tried-and-true patterns: feature flags, canary releases, A/B tests, and friends. While you can continue to take advantage of traditional feedback mechanisms - product metrics and technical observability - look to AI evals for a purpose-built objective measure of your LLM's performance.
The teams that will create the most compelling AI-powered products aren't necessarily those with the most sophisticated prompts or the latest models. They're the ones who can iterate fastest while maintaining quality, and Progressive Delivery is how you get there.






























OpenTelemetry, without the vendor lock-in: Introducing full observability for Open Source and Self-Hosted Flagsmith customers

































































.png)
.png)

.png)

.png)



.png)












.webp)