
8 Types of Deployment Strategies (And How Feature Flags Help)



In software development, every new feature is a leap into the unknown and brings up questions like: will this work as intended, is it going to be well-received by the users, and will it introduce new bugs?
Traditionally, engineering teams have rolled out large batches of changes all at once—often to the entire user base. Sometimes things go smoothly, but the results can be catastrophic when they don’t. Frustrated users, lost revenue, and long nights with engineers scrambling to fix problems in a hurry are just a few of the consequences.
Enter: feature flags. Feature flags allow you to decouple deployments from releases, changing how you approach software delivery. If you don’t want to roll out changes in your code all at once or generally want to take a safer approach to deploying code, feature flags or toggles offer an excellent way to reduce risk.
In this article, we’ll explore different deployment strategies and how feature flags can support each approach—so you have more control over your releases.
Types of deployment strategies with feature flags
Here are eight different types of deployment strategies that feature flags support:
1. Big bang releases
A big bang release is the most straightforward approach to releasing software. You build your changes, test them, and then release them to all users simultaneously (usually overnight). One moment they’re using version 1.0, and the next, they’re thrust into version 2.0. It’s the software development equivalent of ripping off a band-aid—quick, decisive, and occasionally painful.
When you deploy this way, you replace your entire application in one fell swoop. There’s no complex orchestration of servers, no percentage-based rollouts to manage, and no segment targeting to configure. You simply push the button and watch as your new code makes its way to production.
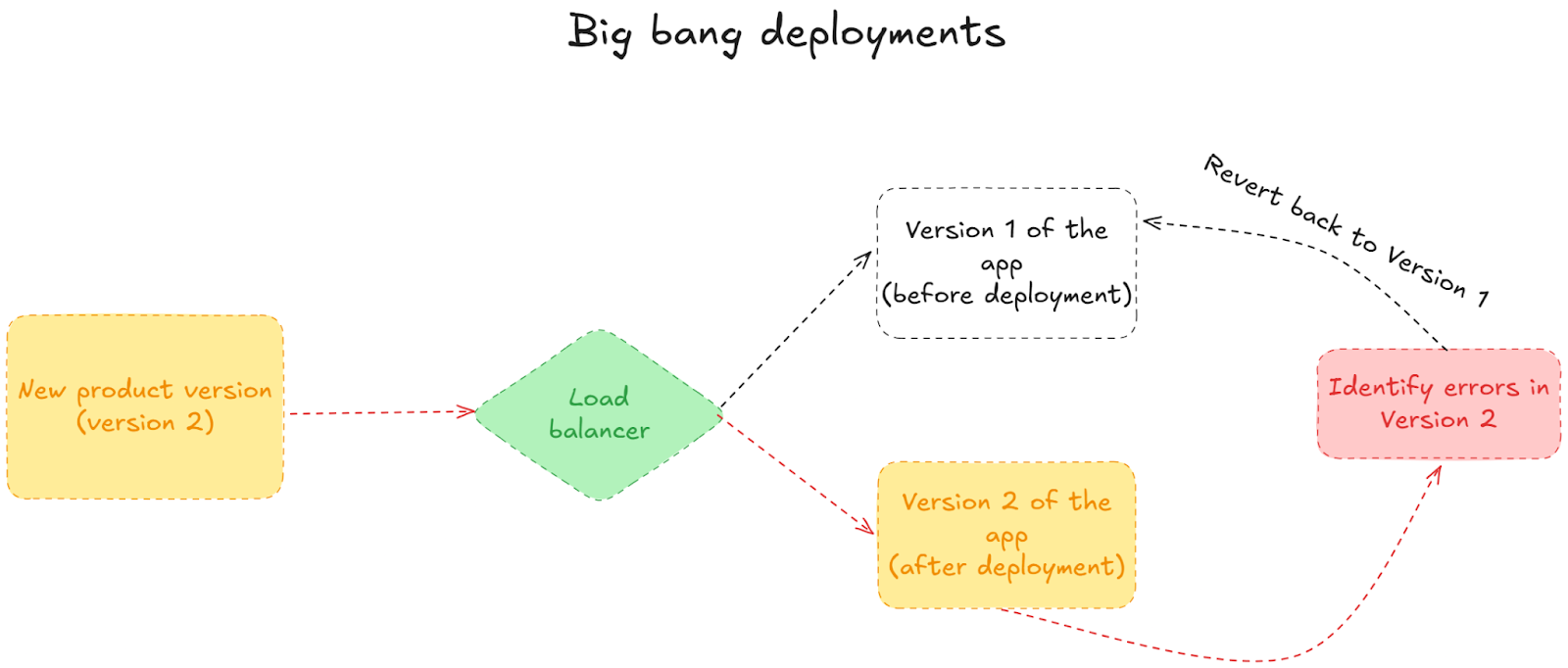
But this also means a lot could go wrong. For example, if you’re launching a new security update and there’s a bug, 100% of your users will experience it. The rollback process results in downtime for long periods—affecting user experience and maybe even your bottom line.
Many brave software teams still choose to use Big Bang deployments. But it’s very risky, and the consequences can be severe, as we saw with Crowdstrike last summer. If you want to derisk this process, you'd be better off moving away from Big Bang deployments and using feature flags to control the experience and decouple deployment from release.
Unlike big bang releases where you release everything at once to all users, feature flags fundamentally change your approach to releases. With feature flags, you deploy code that’s “off” by default, then gradually turn features on for specific user segments. This way, you can test the impact the changes on real users before scaling. If something goes wrong, you can turn off a problematic feature in seconds without redeploying code.
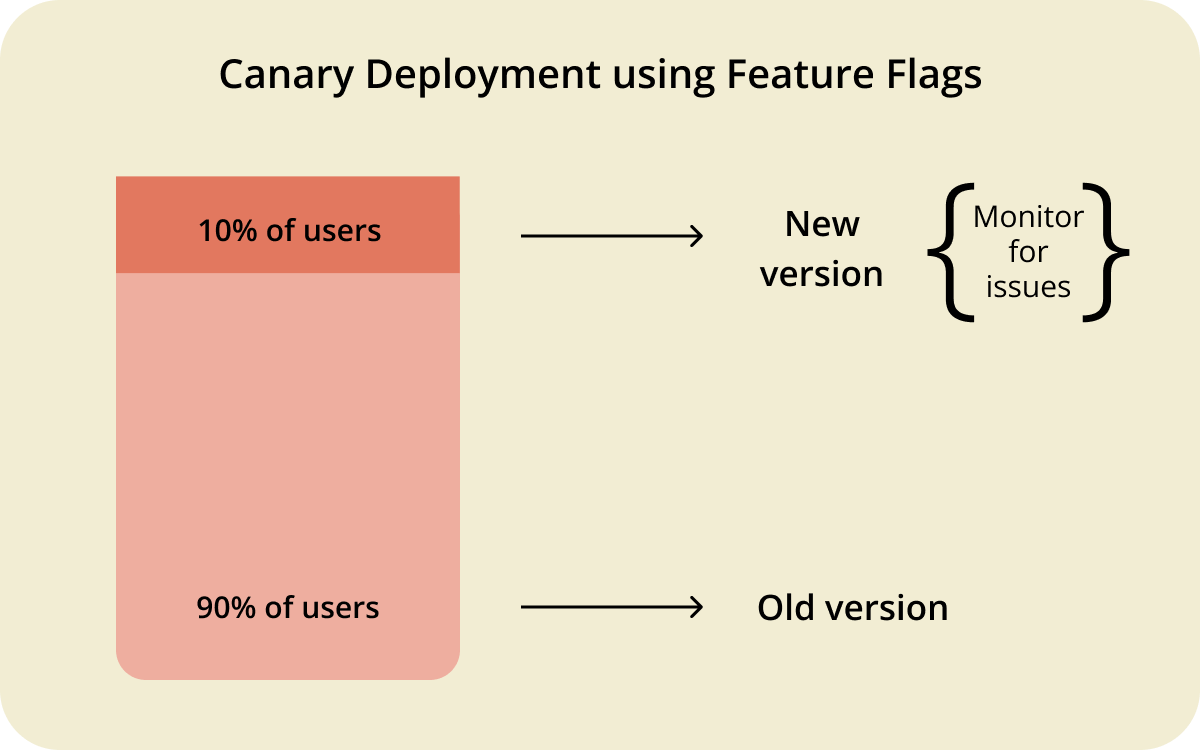
2. Canary deployment
Canary deployments are named after the historical practice of coal miners bringing canaries into mines to detect toxic gases. If the canary stopped singing (or worse, keeled over), miners knew they needed to evacuate immediately.
Similarly, in software development, you can release new code to a small subset of users, evaluate its performance, and then gradually roll it out to more users if everything’s OK. If the proverbial canary stops singing—AKA a feature is not behaving as expected—you can fix it before rolling it out to a wider audience.
Do I need feature flags for canary deployments?
While you could implement canary releases without feature flags (using things like traffic splitting at the network level), it’s not ideal. You won’t be able to see what’s wrong unless you have the right analytics in place.
Other than that, it’s also hard to roll back changes. Typically, you’ll wait for your team to create a new pipeline to roll back the changes and redeploy as needed. But with feature flags, all you have to do is flip the switch and turn individual features off—no need to do a massive rollback.
For example, you might create a flag called new-payment-processor and initially enable it for 1% of users. If metrics look good, you can increase it to 5%, then 20%, and so on until it reaches 100%. And if the new payment processor starts rejecting valid credit cards or double-charging customers? Just flip the flag off, and everyone will revert to the old, reliable system while you figure out what went wrong.
3. Blue-green deployment
Blue-green deployment is a technique that reduces downtime by simultaneously running two identical production environments, called Blue and Green. At any time, only one of the environments is live, serving all production traffic.
Let’s say Blue is currently handling all your users’ requests. In the meantime, Green sits idle, waiting for its moment to shine (and by "shine," we mean "handle thousands of API calls per second"). When you want to release a new version of your application, you deploy the changes to Green while Blue continues to serve traffic undisturbed.
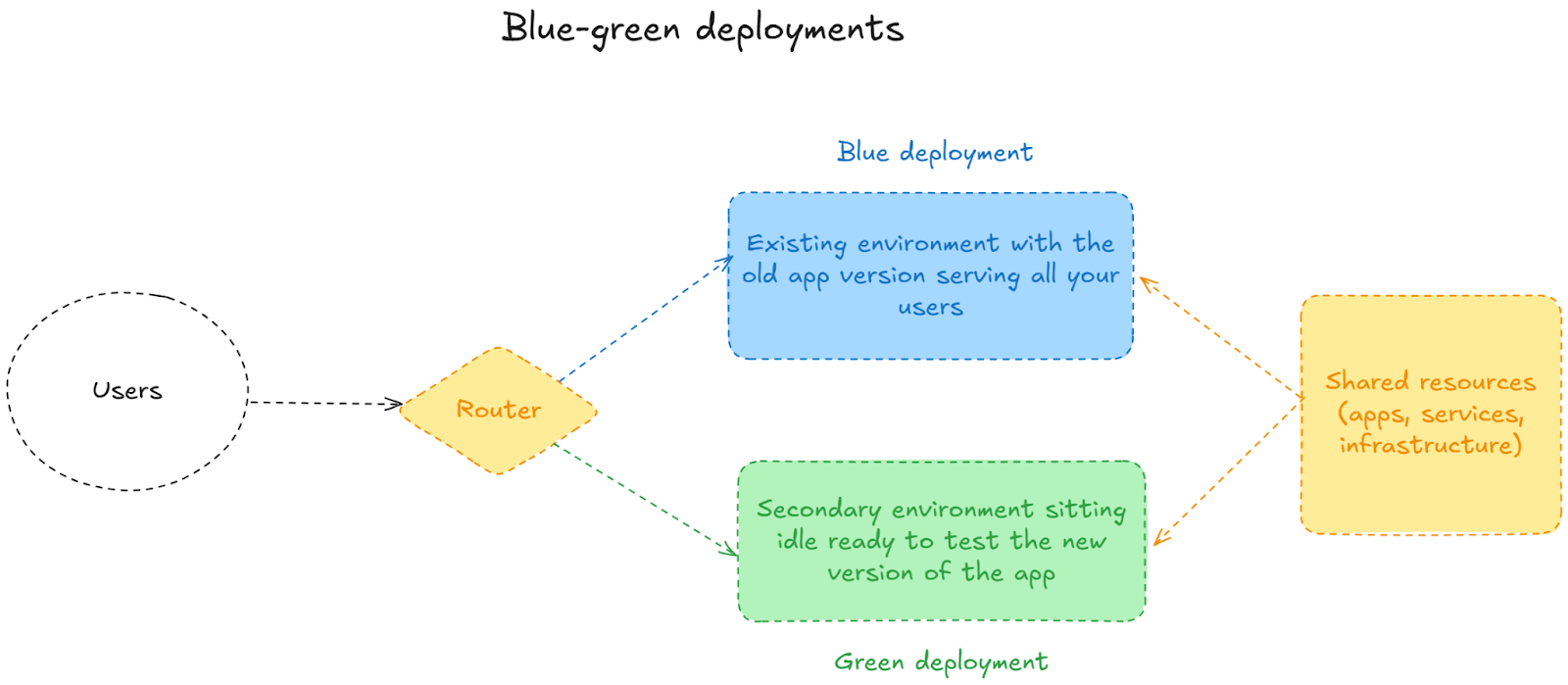
The process works like this:
- You deploy the changes to the environment that isn’t live—in our example, it’s Green.
- You run tests to ensure everything works as expected and catch issues before they affect users.
- When you’re satisfied that the new version is ready, you switch the router so that all traffic goes to the updated environment (Green). The previous live environment (Blue) becomes idle.
If issues are discovered, this strategy allows for quick rollback—you switch traffic back to the previous environment.
Do I need feature flags for blue-green deployments?
Many teams still use blue-green deployments and deploy them through infrastructure changes. But adding feature flags to the mix significantly upgrades that process.
These toggles complement blue-green deployments, giving you even more control over the transition. Instead of immediately switching all traffic from Blue to Green, you can use feature flags to gradually shift users from one environment to another. And with feature flagging platforms that have built-in analytics, you can see what’s happening in real-time.
4. A/B testing
A/B testing is a strategy for comparing two versions of a feature to determine which one performs better against specific metrics. You form a hypothesis, test it with real data, and decide based on the results. Other deployment strategies are mostly about reducing risk, while this is about making data-driven decisions.
In an A/B test, users are randomly assigned to see either version A (the control) or version B (the variant). Then, you measure their behaviour to see which version gets better results. For example, if you want to test if your new patient onboarding system leads to higher completion rates, you can test it using this approach.
Do I need feature flags for A/B testing?
Feature flags are essential for A/B testing initiatives. Without it, you’ll waste time writing custom code for each test and struggling to redirect traffic to the winning variant when the results are out.
With feature flags, you get precise audience targeting and segmentation capabilities. You can divide traffic randomly between variants A and B and create controlled experiments for specific user segments. For example, if you want to test the onboarding system on iOS devices only, you can add a device-specific feature flag to run the test.
The best part is that you can adjust the percentage of users seeing each variant on the fly. If you started with a 50/50 split but want to increase exposure to the winning variant? Just adjust the flag configuration without touching the code.
🏴 Pro tip: Use a feature flagging platform that integrates with your favourite analytics tool to get a holistic overview of the test’s impact.
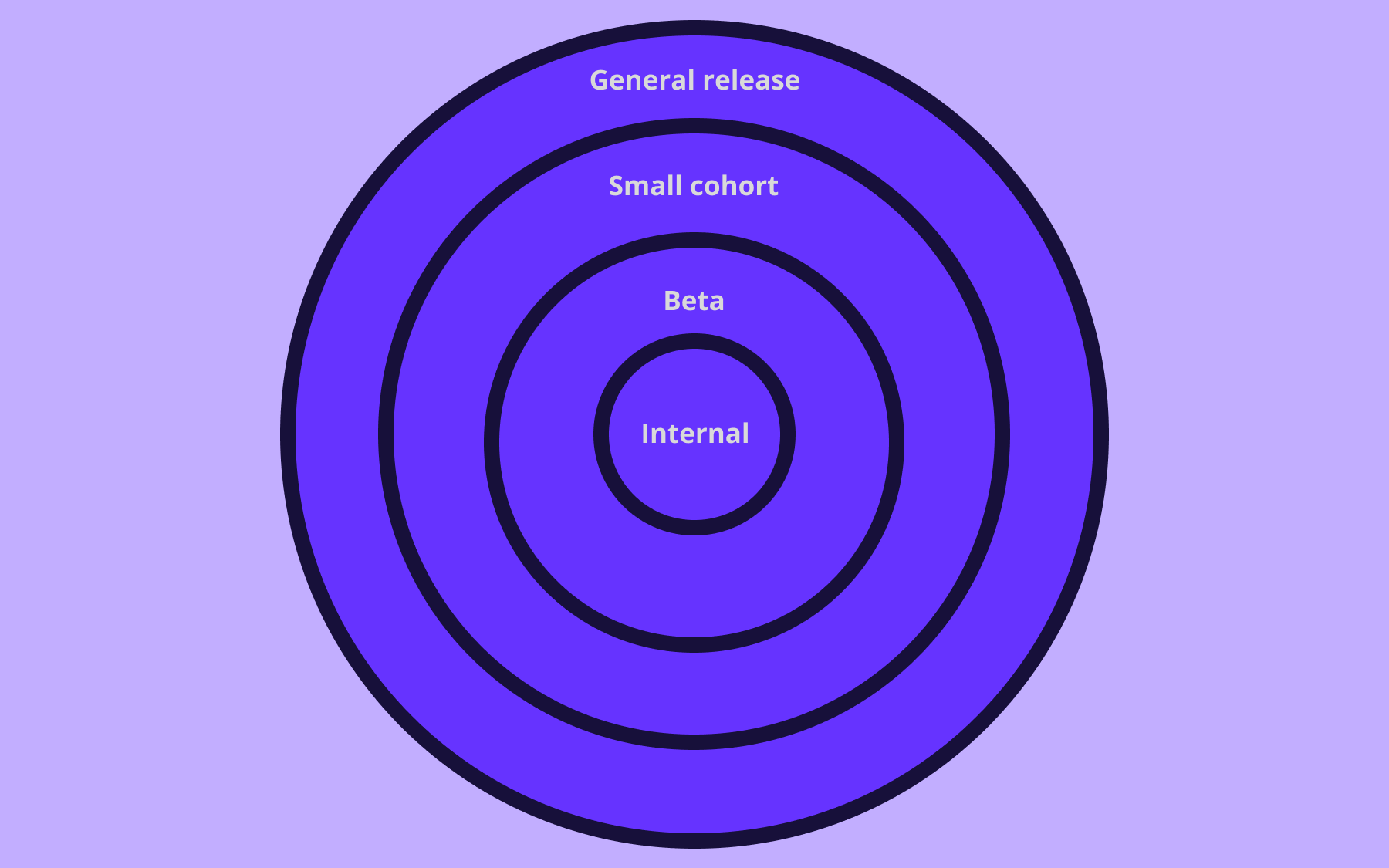
5. Progressive delivery
Progressive delivery works on the principles of continuous delivery, but the difference is it adds gradual rollouts with real-time monitoring. This approach combines different deployment strategies like canary and blue-green deployments.
The main idea is to minimise risk by releasing changes to small audiences first, gradually increasing exposure, and being able to roll back if you see any issues. For example, if you’re testing a new permit application feature in your app, you could:
- Roll it out to internal testers for quality assurance
- Do a beta release after QA to users in a specific demographic
- Gradually release the application to other users
- A/B test the current application form against the new one
- Fully roll out the winning variant to all your users with confidence
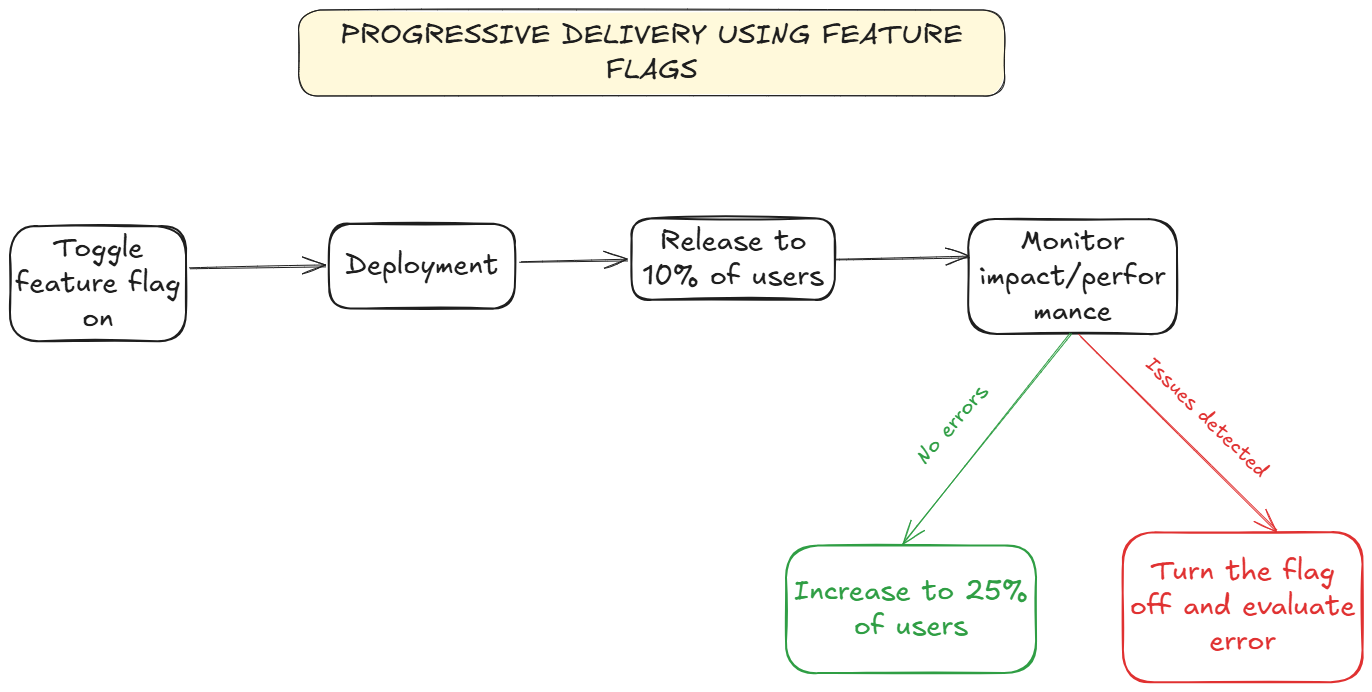
Do I need feature flags for progressive delivery?
Progressive delivery fundamentally requires feature flags to work well. For staged rollouts, you can define specific user segments (e.g., internal users, beta testers, paying customers). You might start by enabling a new feature for your development team, then expand to all internal employees, then to your beta tester program, and finally to your general user base.
As you scale this approach across multiple teams and features, it could get chaotic. You need a centralised system to deliver features progressively—with confidence. Platforms like Flagsmith give you that capability so that you can:
- See which features are enabled for which users
- Integrate with monitoring and analytics tools to get complete coverage
- Access audit logs to see who’s deploying code and where
6. Rolling deployments
Rolling deployments (sometimes called "rolling updates") involve gradually replacing instances of the previous version of an application with instances of the new version. It’s common in containerised environments and managed platforms like Kubernetes, where the infrastructure is already designed to support this.
During a rolling deployment, the platform might replace instances one by one or in small batches. As a result, the services remain available to your users throughout the change. As and when the new version is deployed, you can automatically redirect traffic to it. There’s no downtime, as you always have enough capacity to handle the traffic.
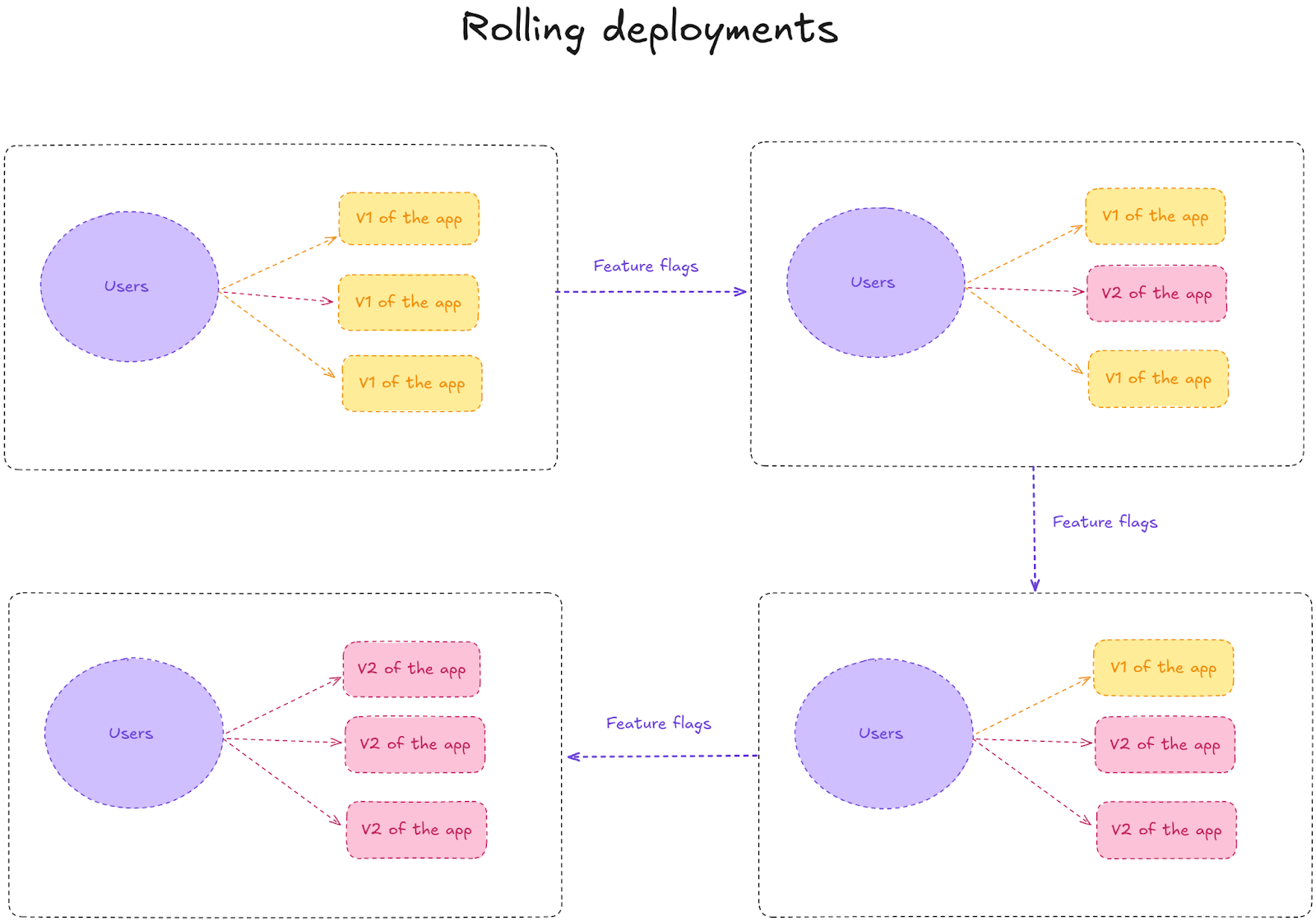
Do I need feature flags for rolling deployments?
You can conduct rolling deployments without feature flags—but if you combine them, you can do it more efficiently. The infrastructure handles the mechanics of safely replacing running instances, while feature flags control the activation of new functionality.
Let’s say you’re rolling out a new security update for your banking app. And you’re using a containerised Kubernetes environment for the API. With a rolling deployment strategy, you can replace instances of the old authentication service in small batches using feature flags.
If you update 10% of the instances, 90% continue to run on the old version. Your engineers monitor authentication success rates and error logs. If everything looks good, you roll it out to 30%, then 50% and eventually 100% of instances. See how rolling deployments compare to blue-green and other deployment options in our blog.
7. Shadow deployment
Shadow deployment is a technique where you send production traffic (or a copy of it) to a new version of your service running in parallel with the live version but don’t actually return the results to users. It’s great for testing performance, resource consumption, and identifying potential errors in your code. But it’s also generally good for test-driving the code before rolling it out.
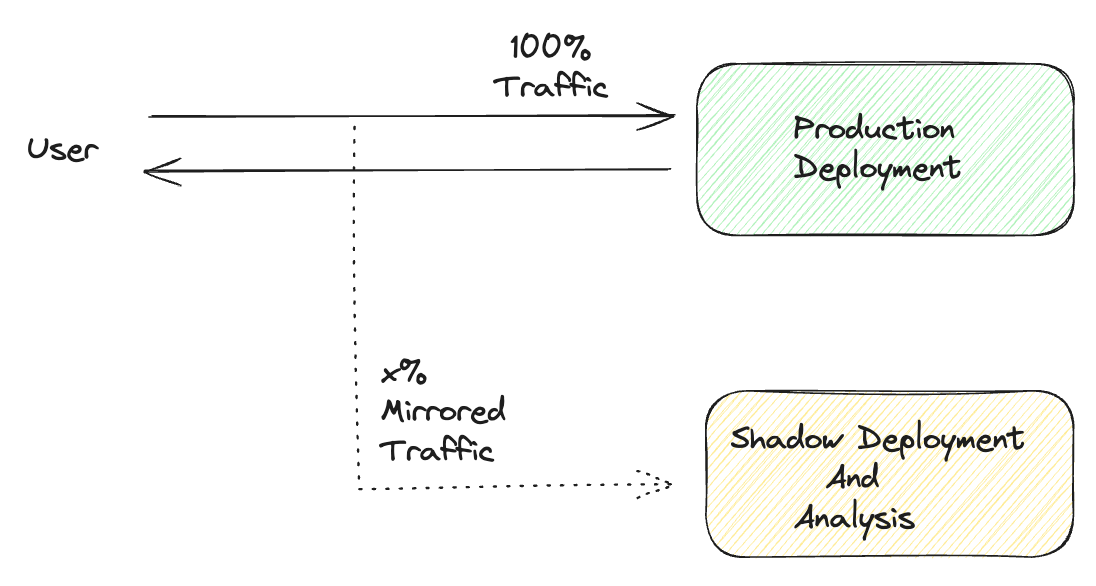
For example, if you’re replacing a critical payment processing system, you can deploy the new version in shadow mode, sending it copies of all incoming payment requests. The current system still handles the actual transactions, while the new system processes them in test mode (not actually charging cards or moving money). You can then compare the results and make better decisions.
Do I need feature flags for shadow deployments?
It’s possible to implement shadow testing with hard-coded rules or configuration files. However, a feature flagging solution gives you finer control over the process with precise data on the impact of your deployment.
Let’s say you’re implementing a new medical records processing system across multiple states. You could use this method with a feature flagging tool to shadow test non-urgent outpatient records first, then slowly work towards inpatient and emergency records once your tests succeed. You can set up all the targeting rules in minutes without needing to write new blocks of code.
8. Recreate deployments
Recreate deployment is the simplest deployment strategy and involves a rip and replace, where you completely remove the old version and deploy the new one—all at once. Most engineering teams use this approach when the application can’t support multiple versions that run simultaneously.
It’s also a good choice when downtime is acceptable (scheduled maintenance windows at 2 AM, for example) or when the deployment needs to make breaking changes to shared resources like databases. That said, you can’t just revert to the old version as easily as you deploy the new version.
Do I need feature flags for recreate deployments?
Recreate deployments are very high-risk deployments. The biggest problem is the inability to revert easily. But feature flags make that possible. With feature flags in place, you can deploy your application with all new features in a disabled state. This allows you to verify that the basic system functions correctly before gradually rolling out new capabilities.
If you want to derisk the deployment completely, you’ll be better off with canary deployments or progressive delivery strategies.
Deployment strategies as part of the broader software development life cycle
Deployment strategies are integral parts of your broader SDLC and modernisation efforts. When you combine them with feature flags, they can change how your organisation approaches software delivery.
The most important benefit is the ability to separate deployment from release. It reduces the number of environments you need to work in and allows you to only release code when you feel ready—rather than waiting on other teams and coordinating your releases with them.
And it’s because of this ability that you can move fast without breaking things. You can build a faster feedback loop and respond to issues faster without rolling back entire deployments. And if you want to try new approaches, feature flags make creating an experimentation culture less risky and smoother.
But if you look at it from a larger perspective, you’ll soon realise that, ultimately, feature flags allow you to modernise your software development process. Whether you’re planning a move from a monolithic architecture to microservices, merging two apps, or migrating users and components from a legacy system to a new one, they can help with a smooth and gradual transition that reduces risk.
These approaches can be particularly valuable in data-sensitive industries like banking, healthcare, and insurance. In these industries, the stakes of modernisation are high, and the appetite for risk is low.
Which type of deployment strategy is best for you?
There’s no one-size-fits-all approach to deployment strategies. You may find that one strategy works best right now—or maybe a combination of strategies, depending on your deployment needs. You can use the following factors to make a better decision:
- Risk tolerance: Use canary deployments if you have a low-risk tolerance. But if you need to revert quickly, choose blue-green deployments.
- Application architecture: If you use monolithic architecture, choose blue-green deployments for a cleaner cutover. But if you’re using microservices, you’ll be better off with rolling or progressive delivery strategies.
- Business needs: If you want to test with specific user segments first, choose progressive delivery strategies.
Irrespective of whichever deployment strategy you use, feature flags are essential. With solutions like Flagsmith, you can easily create and manage them while accessing an additional layer of control that makes your deployments safer and more flexible.


























OpenTelemetry, without the vendor lock-in: Introducing full observability for Open Source and Self-Hosted Flagsmith customers

































































.png)
.png)

.png)

.png)



.png)












.webp)