
Moving to Progressive Delivery with Feature Flags



“Move fast and break things.” We've heard this countless times. But the best engineering teams ask a better question:
“How do we move fast without breaking things?”
When you’re in a highly-regulated sector, the stakes are high. You must constantly keep up with customer (and market) demands, but your requirements around compliance and risk-reduction remain the same. If you’re using older techniques like Big Bang deployments, every release comes with a risk of failure. The more you ship, the higher the risk.
Take the CrowdStrike incident, for example. for example. A single update to their Falcon sensor affected Windows systems globally, resulting in a major outage within critical industries like airlines and government services. Careful planning and minimizing risk are essential in modern deployment strategies, especially when rolling out incremental or staged updates.
For teams that don’t want to risk it all with every deployment, progressive delivery provides a safer approach. By exposing new features to a small segment of users initially, teams can collect valuable data on how the feature is being used and how well it performs in the real world before a full rollout.
In this guide, we’ll explain how progressive delivery works and how to do it well using feature flagging and modern observability tools.
What is progressive delivery?
Progressive delivery is a deployment strategy that involves continuously deploying code to production but controlling who sees it and when. It builds upon continuous delivery practices by giving you fine-grained control over feature releases. Progressive delivery represents a modern, strategic approach to software deployment that emphasizes controlled, incremental rollouts to reduce risk.
Progressive delivery using feature flags
With progressive delivery, you introduce changes to small subsets of users first, often rolling out features in multiple stages to targeted audiences. You monitor the impact and gradually increase exposure as you gain confidence. At each stage, you gather feedback from users to inform further rollout decisions.
This controlled exposure model creates a safety net for deployments. Instead of shipping and praying it works, you get multiple decision points to evaluate if releasing is the right thing to do. This approach ensures stability and quality before releasing features to the entire customer base.
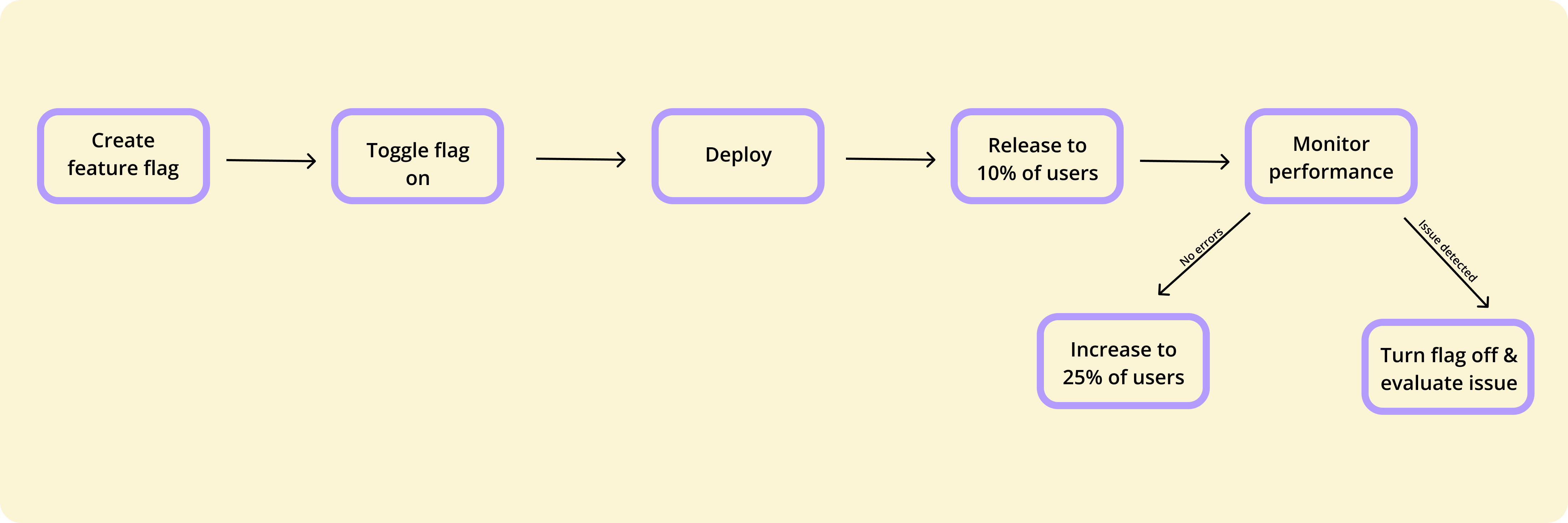
Progressive Delivery vs. Continuous Delivery
Continuous Delivery methods automate your build, test, and deployment pipelines, meaning engineering teams can ship code frequently and reliably. Also at the core of these modern software development practices is continuous integration, which ensures that code changes are automatically tested and merged, improving release frequency, quality, and reliability. However, once deployed, changes are exposed to all users immediately without a failsafe.
This is where progressive delivery differs. It adds a layer of control where you can still deploy frequently through your CI/CD pipeline, but you decide when and to whom the features become visible. Progressive delivery takes traditional methods like continuous delivery further by emphasizing controlled, incremental releases of features, often using feature flags, A/B testing, and real-time user feedback to improve product quality and reduce risk.
In Continuous Delivery, you mitigate risk primarily through pre-production testing, trying to catch issues before they hit end users (occurring at the infrastructure level and automating shipping). But with progressive delivery, you distribute that risk through limited exposure and rollback capabilities with tools like (occurring at the software level).
How engineering teams have “shifted left” to progressive delivery and observability
Fifteen or so years ago, the classic 3-tier application stack—web server, app server, and database—ran on relatively static infrastructure. You made changes infrequently, and traditional monitoring tools used simple statistical baselining to detect problems.
But today, the approach looks drastically different. Your infrastructure runs on multi-layered virtualised stacks spanning virtual machines (VMs), Kubernetes, or other serverless platforms.
In many cases, teams are breaking down monoliths and embracing interconnected microservices with numerous third-party integrations throughout the architecture. And now, everyone wants to move faster, so deployments happen continuously rather than on fixed schedules. The development team now plays a more active role in feature development and testing throughout the delivery process, iteratively improving features, and managing issues as they arise.
It doesn’t make sense to introduce observability only after you’ve deployed the code. In fact, the more you shift left, moving testing and quality evaluation earlier in the process, the more problems you can prevent.
Embrace progressive delivery to foster collaboration and continuous improvement by enabling incremental, risk-managed deployments and leveraging techniques like canary releases and A/B testing.
Among the most powerful deployment tools at your disposal are feature flags, which give you the ability to toggle new features on or off without deploying new code. This fine-grained control over your delivery process means you can test new features with a small percentage of your users and monitor their experience closely, minimising risk before you commit to a full rollout.
For instance, Flagsmith integrates with tools like Grafana to de-risk progressive rollouts. You can define your observability requirements during design and collect the data you need to make better decisions throughout the development lifecycle.
How feature flagging and observability work together
It’s important to understand that observability and progressive delivery work hand in hand. As feature flags enable controlled releases, observability gives you more confidence by showing you how the features behave in production.
Monitoring system performance is crucial during progressive delivery, as it helps validate that new updates do not negatively impact stability, speed, or operational efficiency. Together, they create a feedback loop where data drives progressive rollout decisions.
Without proper observability, feature flags feel risky. You might toggle features on or off but remain blind to their effects. Conversely, without feature flags, observability data might reveal problems, but you’d lack granular control to deal with them quickly.
In short, engineering teams that incorporate both these tools to deliver features progressively do the following:
- Reduce operational risk as fewer users experience problems
- Lower costs because issues are detected earlier
- Pass compliance requirements using detailed audit logs
- Collect valuable data from real-world users, such as feedback and performance metrics
With these tools, teams can make data-driven decisions that continuously enhance feature rollouts, optimizing deployment strategies and improving product quality.
How do feature flags power progressive delivery?
Progressive delivery requires you to deploy code without immediately exposing new functionality to users. Feature toggles enable this by letting you wrap code to control the release of this functionality.
A major benefit is that developers can make more informed decisions and automate deployment processes, streamlining the path from code to production—they can merge code into the main branch more frequently.
You don’t have to expose incomplete or untested features, or wait until they’re fully ready to deploy them. Additionally, and this is key, these tools also give product teams more control over the release process without needing a developer to help.
When you actually release and the data flows through observability tools, you can see how it performs in a real user environment. Interestingly, the relationship between feature flags and observability runs both ways. You see how your feature performs using observability tools, and in turn, you can use that data to turn flags on or off automatically (based on certain thresholds). Tracking user engagement is a key metric here, helping teams evaluate the success and acceptance of new features or updates.
In this webinar, Kyle Johnson, Co-Founder of Flagsmith, and Andreas Grabner, Global DevRel at Dynatrace, explain how the Flagsmith and Dynatrace integration helps engineering teams:
- Directly correlate user experiences with specific feature configurations. For example, you can see if users with a new payment processing flow enabled are experiencing higher error rates than those with the feature disabled.
- Segment metrics based on feature flag states to compare different variations and see what works best.
- Set up automated responses based on specific thresholds, allowing for direct comparison between different variations.
Your entire team will become more comfortable shipping incremental changes when they know the release process includes safety mechanisms.
How to build a progressive delivery pipeline with the right tech stack
Let’s say you’re the lead developer for a mid-sized banking application. Your team has built a redesigned onboarding flow that promises to increase conversion rates and reduce customer support tickets. If you want to make sure it works, try the progressive delivery method. Your rollout could look like this with Flagsmith, Grafana, and Dynatrace:
- Create the flag: Using Flagsmith, set up a flag called ‘newonboardingflow’ to control access to the new onboarding module.
- Test with internal users: First, enable the feature for employees and staff members so they can test the new onboarding flow, provide early feedback, and help identify issues before exposing it to external customers.
- Conduct a gradual rollout: Incrementally expose the feature to larger user segments. For example, you might start with 10% and increase the percentage to 20%, 30%, and so on. During this process, use traffic shifting to control the flow of production traffic to the new feature, mitigating risk with the gradual routing of user requests.
- Monitor performance: Track performance and user metrics across both versions. With Grafana, you can use annotated queries to see how increasing the percentage affects user behavior. And with Dynatrace, you can monitor issues in real time and mark the feature as “healthy” or “critical” depending on the data. Observability is paramount here, enabling you to track service-level objectives and user experience metrics.
- Expand or rollback: Based on the observability data, either continue the rollout or revert to the previous version.
Note: Flagsmith also has a “Feature Health” capability that lets you monitor the feature’s status and performance within the platform.
How progressive rollouts enable more testing
Managing multiple versions of a feature or service in production can increase complexity, so it’s important to have robust processes in place.
What sets successful development teams apart in today's competitive digital landscape is how they release new features—how carefully, strategically, and user-focused their deployment approach is.
That’s where testing comes in, helping your team discover what users truly want, how they engage with your product, what causes issues, and how to deliver features that delight rather than disappoint.
Instead of releasing new features to all your users at once, you enable them for a small subset of users—controlled exposure that allows your team to gather valuable feedback and performance data from real users in production, without risking the stability of your entire system.
Deployment tactics, tools, and techniques to consider
Canary deployment
So, how do you implement this approach effectively? A common method is canary deployment, where you release a new version of your application to a limited group while the majority of your users continue to use the previous version.
Your team can monitor user feedback, track performance metrics, and identify any issues early in your release process. Real user data is at the center of your decision-making, so as user confidence in your new features grows, you can expand the rollout to more people—always in a data-driven manner that reduces guesswork and maximizes success.
Adopt progressive rollout and testing to empower your team to make informed decisions about when to advance or pause releases, ensuring that only well-tested, high-quality features reach your entire user base.
This iterative process not only minimizes risk but also fosters continuous improvement and higher user satisfaction. Otherwise, businesses risk making deployment decisions based on assumptions, which could cause increased user frustration and system instability. With a progressive process in place, you can deliver an excellent user experience that significantly improves customer retention and reduces support costs.
Blue-green deployment
Another widely used tactic is blue-green deployment, which involves maintaining two identical production environments—commonly referred to as the blue and green environments.
Your current version of the application runs in one environment, while you deploy a new version to the other. By directing user traffic between these two identical production environments, your team can seamlessly switch to the new version or quickly revert to the previous one if issues are detected, minimizing downtime and data loss.
Service meshes
Service meshes provide your team with advanced traffic routing capabilities.
They enable you to control how user requests are distributed between different versions of your application, allowing for fine-grained management of progressive rollouts and feature releases that make a positive impact on your users.
Combined with automated testing and robust monitoring tools, these deployment tactics help your team detect issues early and respond rapidly, keeping users satisfied throughout your software delivery process.
By integrating tactics like canary deployment, blue-green deployment, service meshes, and automated testing into your deployment pipelines, you ensure that new features are delivered in a controlled and user-centric manner.
Your users will enjoy a seamless experience, while your team will grow in confidence with every release.
What are the common pitfalls to avoid when using progressive delivery?
Here are the most common issues teams encounter when implementing progressive delivery—and how to avoid them:
Building resiliency into system components is crucial when you’re handling multiple versions running in parallel during progressive delivery.
Additionally, adopting robust feature development practices helps teams avoid many common pitfalls associated with progressive delivery.
Here are some common pitfalls to avoid.
1. Neglecting feature flag archiving and cleanup
Feature flags are inherently temporary control points, with a few exceptions like kill switches. If you leave them in your codebase after they’ve served their purpose, it creates “flag debt” that bloats your codebase and could cause serious unintended app behavior.
You might add a flag today for a major release, but six months later, no one remembers why it exists or whether they should remove it. Maintaining hygiene by regularly cleaning up old feature flags is essential if you want to prevent technical debt and complex dependencies.
Pro tip: Follow feature flag best practices like creating a flag lifecycle policy and naming convention to avoid this issue. Document the purpose of each flag along with on and off dates. If it’s a long-lived flag, explain why that’s the case.
2. Not setting up the observability tools properly
If you can’t see what’s happening with your flag, it could lead to blind spots in your development and production environment.
For example, a team might roll out a new driving license application portal to 5% of users. But without proper monitoring, they miss that the new portal is increasing onboarding times by 30%.
The best observability systems include real-time alerts, user behavior analytics, and system performance dashboards specifically tied to feature flag states. Teams can then quickly detect issues and correlate performance changes directly to progressive delivery activities.
Pro tip: Think about the three pillars of observability: metrics, logs, and traces. Set up your monitoring in a way that covers the impact and performance.
3. Not preventing misalignment between developers and product teams
Let’s say your product team wants to roll out a feature to a specific customer segment, and they’ve decided to use an existing flag. The flag may already have a purpose—for example, your developers could’ve set it up to conduct another test. If you don’t have the context (and documentation) to be sure you can use this flag, you could be causing more problems by switching it back on.
As a result, you flip the switch, and next thing you know, your entire app is experiencing downtime. Involving the whole team in the progressive delivery process keeps everyone aligned so you can avoid these kinds of missteps.
Pro tip: Document every flag’s purpose in a living document to share with the product team. Also, make sure you implement role-based access (RBAC) to only allow the right stakeholders to make changes to the flags.
4. Complicating the flag’s usage and not accounting for nested dependencies
You might become so comfortable with feature flags that you start implementing them without realising how they affect the entire live environment.
Never nest flags more than one level deep, and do this sparingly. You want to avoid creating a web of conditionals that complicate observability and performance measurement.
Pro tip: Always check if a flag impacts other components in your environment. If you want to avoid this issue altogether, maintain solid documentation around feature flags. You can use a feature flagging platform like Flagsmith to track these dependencies.
5. siloing flag data from other platforms in their tech stack
If you use a feature flagging platform, don’t let the data just sit there. Consider integrating it with tools like Grafana or Dynatrace to let them talk to each other and connect the dots between flag changes and impact.
For instance, your team might struggle to tally a sudden increase in drop-off rates with a flag change if they don’t communicate. As a result, you can’t respond faster because you’ll spend hours just teasing out the root cause.
Pro tip: If you don’t have access to specific integrations, use webhooks or APIs to push the flag analytics data into other relevant data tools.
Progressive delivery de-risks deployment and lets you release with confidence
The tension between speed and stability doesn’t need to be a zero-sum game. Progressive delivery enables organizations to move faster and release software more safely by gradually rolling out changes and monitoring their impact.
Teams ensure customers have the best possible experience, and by testing hypotheses with real customers before launch, enabling them to create better features and software products to drive business success in real time.
If you’re still deploying features in an all-or-nothing approach, it’s time to make the switch. With progressive delivery, you can make better decisions through real-world feedback and squash the dreaded 3 AM alerts, meaning you confidently ship code without any lingering anxiety.
Frequently asked questions
1. What are the types of progressive delivery methods?
Progressive delivery strategies influence the deployment methods you choose, which could be any of the following:
- Canary deployments, where you route a small percentage of traffic to a new version of your application while directing the majority to the stable version.
- Blue-green deployments, where you maintain two identical production environments: “blue” running the current version and “green” running the new version. The green environment serves as the staging or testing environment, prepared for new releases and thoroughly tested before being promoted to production. Blue-green deployments minimize risk and downtime during the release process by maintaining these two production environments.
- Ring-based deployments extend the canary concept by defining explicit “rings” of users for progressive exposure.
- A/B testing is when you test multiple implementations to determine which performs better according to specific parameters you’ve set.
2. How does progressive delivery work with containerised environments like Kubernetes?
Kubernetes provides capabilities like rolling updates that gradually replace pods, while extensions such as Flagger and Argo Rollouts add sophisticated canary and blue-green patterns. Feature flags complement Kubernetes by controlling functionality within containers, giving you both infrastructure-level and application-level progressive delivery capabilities.
3. What’s the recommended tech stack for using progressive delivery?
Ideally, you need a combination of feature flagging and observability platforms. For example:
- Feature flagging: Flagsmith provides feature flag management with flexible deployment options, comprehensive targeting, and integrations with observability tools.
- Observability (flag impact): Grafana delivers customisable dashboards with annotations that correlate feature flag changes to performance metrics.
Observability (issue detection): Dynatrace offers deep application monitoring with AI-powered problem detection that captures flag states and SLO monitoring to validate release quality.























OpenTelemetry, without the vendor lock-in: Introducing full observability for Open Source and Self-Hosted Flagsmith customers

































































.png)
.png)

.png)

.png)



.png)

















.webp)