
No More Hardening Phases: Testing in the Age of Continuous Deployment


The pace of change is accelerating
There has been a clear trend over the last decade for engineering teams to increase the tempo of production deployments. As the industry moved from Waterfall to Agile, the era of “big bang” quarterly deployments gave way to production deployments that align with sprint cycles, meaning changes going out to production every 2 or 3 weeks.
Now, teams are starting to push even further. Books like Accelerate, and the DORA research team that produced it, have helped the industry understand that the highest-performing teams tend to deploy more frequently. In fact, somewhat counterintuitively, The DORA research shows that teams with a faster deployment tempo tend to deliver higher-quality products, with greater production stability.
Those wanting to really push the envelope of deployment tempo are adopting practices like Trunk-Based Development (eschewing long-lived source control branches) and Continuous Deployment (where every change that lands in a team’s main source control branch is automatically deployed through to production). The combination of these two practices leads to teams that are deploying production changes multiple times a day, if not multiple times an hour.
This hyper-accelerated deployment tempo does present a lot of benefits, but it’s certainly no free lunch. Moving to Continuous Deployment also brings risk, and requires significant changes in a teams’ SDLC—how they build, test and deploy software. In this article, I’ll focus on how testing practices should change as a team accelerates toward Continuous Deployment.
A typical scrum-aligned deployment cycle
To illustrate how your SDLC needs to change as you adopt Continuous Deployment, we’ll contrast it with how scrum teams work when they are deploying to production on a sprint-aligned cadence—usually once every two or three weeks. Of course, every team’s practices are going to vary in the details—this description covers what I most commonly see.
Cutting a release
Many scrum teams will “cut a release” towards the end of their sprint, defining a release candidate—a version of code in a repository which is intended to end up deployed to production. At that point, some sort of short “hardening” or testing phase begins—3 or so work days where that release candidate is subjected to a barrage of quality checks: acceptance testing, regression testing, load testing, and so on. These quality checks will often require the code to be deployed to one or more dedicated pre-production environments, which can go by many names (“staging”, “dev”, “acceptance”, “test”, “QA”, “pre-prod”, “load”, the list goes on). Because these environments are expensive to create and maintain, they are a scarce and valuable resource, shared across many teams.
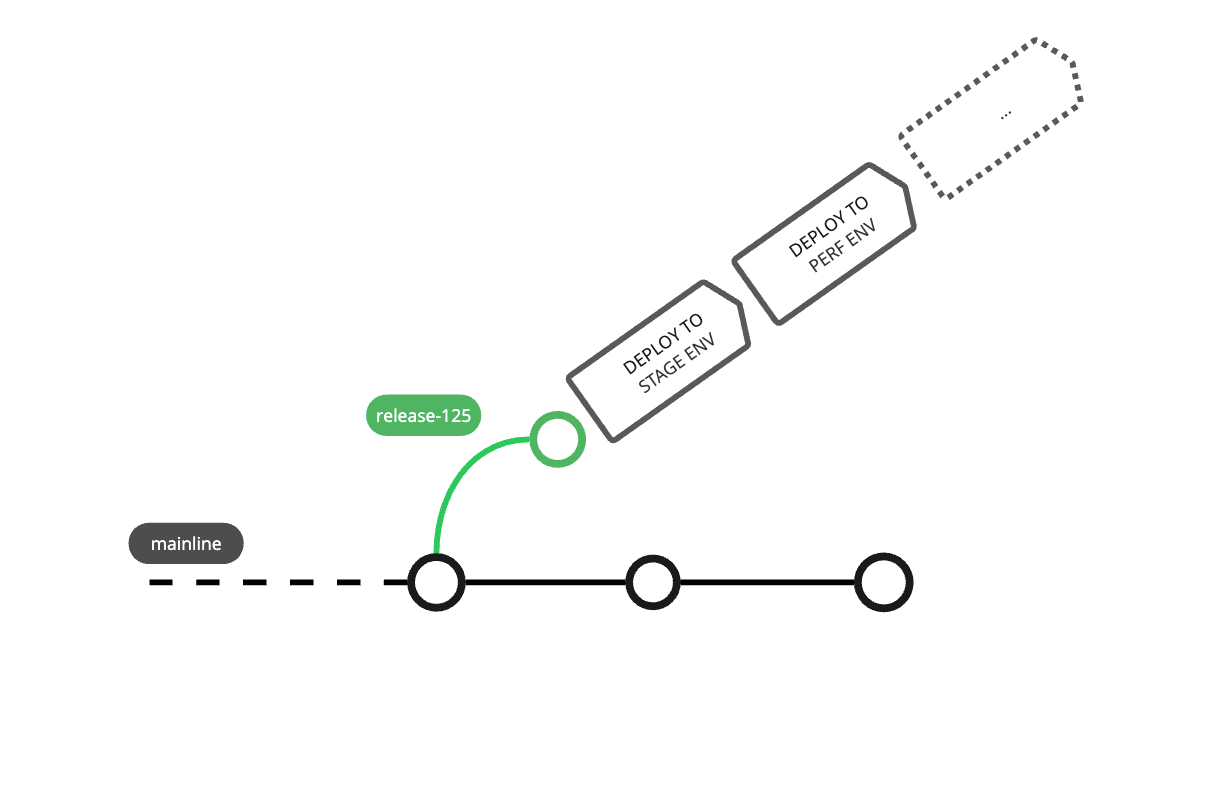
Since this hardening phase usually takes multiple days, product engineers will typically begin working on new features in parallel. Source code branches are used to juggle these two streams of work—an engineer can be working on a new feature in a branch, and switch over to the release candidate branch to address any issues found during testing. These parallel branches introduce some overhead—for one thing, engineers need to bounce between branches, and make sure they are correctly cherry-picking or backporting fixes as appropriate. But it feels like a reasonable trade-off, allowing engineers to start making progress on the next sprint’s tasks.
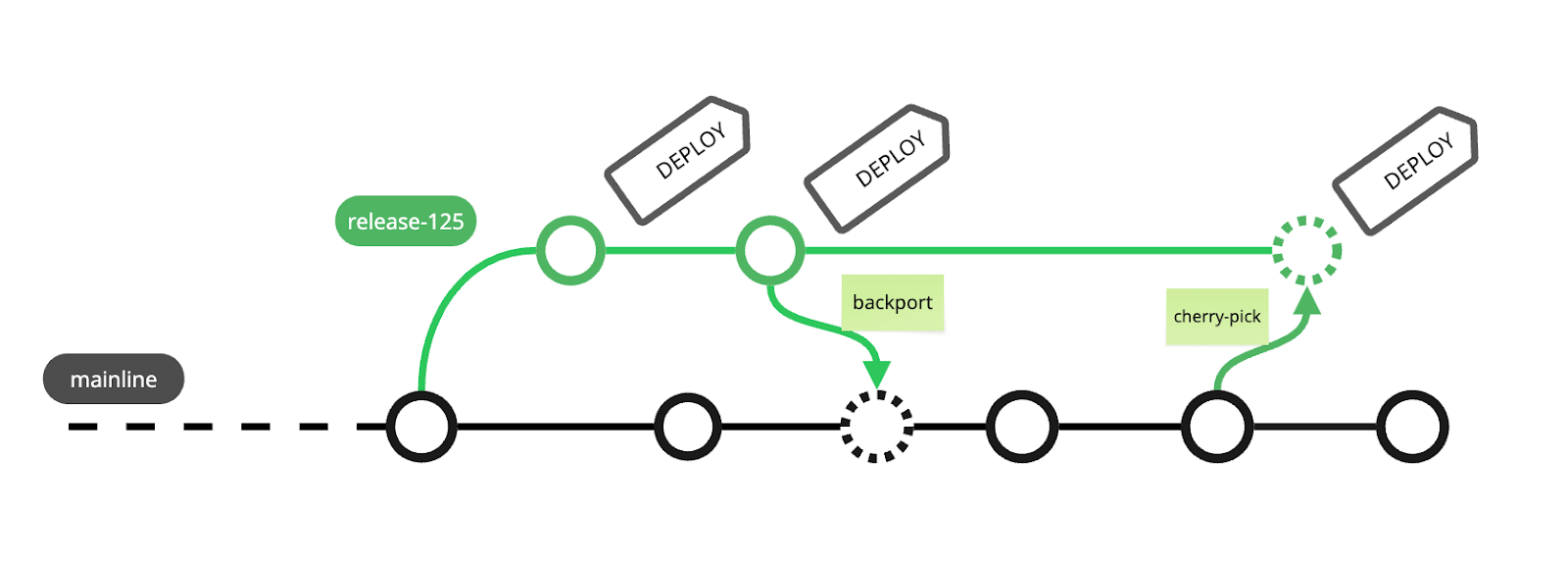
The catch-22 of hardening phases
The fact that this hardening phase requires a release candidate to be deployed to these scarce environments for multiple days creates a challenging catch-22 for teams wanting to accelerate their deployment. If we moved from deploying every 3 weeks to every week, then we’d now be spending a significant amount of our time in that hardening phase. On the face of it, this means three times as much work for people validating the release, as well as engineers spending a lot more of their time bouncing between development branches and release branches.
Given that, deploying once a week seems very challenging, and any pace faster than a week feels truly insurmountable.
So, how are some teams managing to deploy multiple times a day? The first answer centres around batch size. As your deploy cadence increases, the amount of changes going out in any particular deploy goes down. When you’re testing a three-week batch of work, the scope of changes are going to be so broad that your best option is to just regression test the entire system. In contrast, if you’re testing a single day’s worth of changes you can focus your testing on just the areas of the system related to that change. In addition, there’s the obvious benefit that testing one day’s worth of work is just going to take less time than testing 3 weeks of work. Put together, the time needed to validate a particular production deploy is dramatically reduced.
Feature flagging powers Continuous Deployment
Besides batch size, there’s another difference that you’ll see with teams deploying frequently—they use feature flags to separate deployment from release. When engineers start working on a new feature, they use a feature flag to keep the feature hidden from users until it’s complete. This provides two important benefits. Firstly, it reduces the need for long-lived feature branches—partially completed work can be merged into the main development branch incrementally, and even deployed out to production safely because the half-finished feature is hidden behind a feature flag. For the same reason, validation of the feature can be deferred until AFTER deployment to production. Testing of the feature still needs to be done before it is released (by turning the feature flag on), but it no longer has to be done before deployment.
A day in the life of Continuous Deployment
This decoupling of deployment from release, coupled with smaller batch sizes, helps change the entire rhythm of production deployments. Let’s look at what the SDLC looks like for a team that’s moved to Continuous Deployment.
Such a team might still be working in sprints, maintaining the same cadence for rituals like planning meetings, retrospectives, and showcases, but their production deployments now happen ad hoc, throughout the sprint cycle.
When an engineer starts work on a new feature, they will often (but not always) create a feature flag. They might also create feature branches, but they no longer need to develop the entire feature within one feature branch. They can break it into a series of changes, each on their own branch, with each branch being reviewed and merged incrementally. This leads to smaller PRs that are easier to code review, and a faster feedback look from the reviewer—both welcome benefits.
As the engineer’s work lands on the main development branch, it will be automatically built, tested, then deployed to pre-production environments. Further automated tests will run, and if they pass then the change will eventually be automatically deployed to production. This is the difference between Continuous Deployment vs. Continuous Delivery. The latter enforces that any code change on the main branch should be deployable to production at the push of a button. The former automates that button, such that every change which passes automated checks will automatically ship to production.
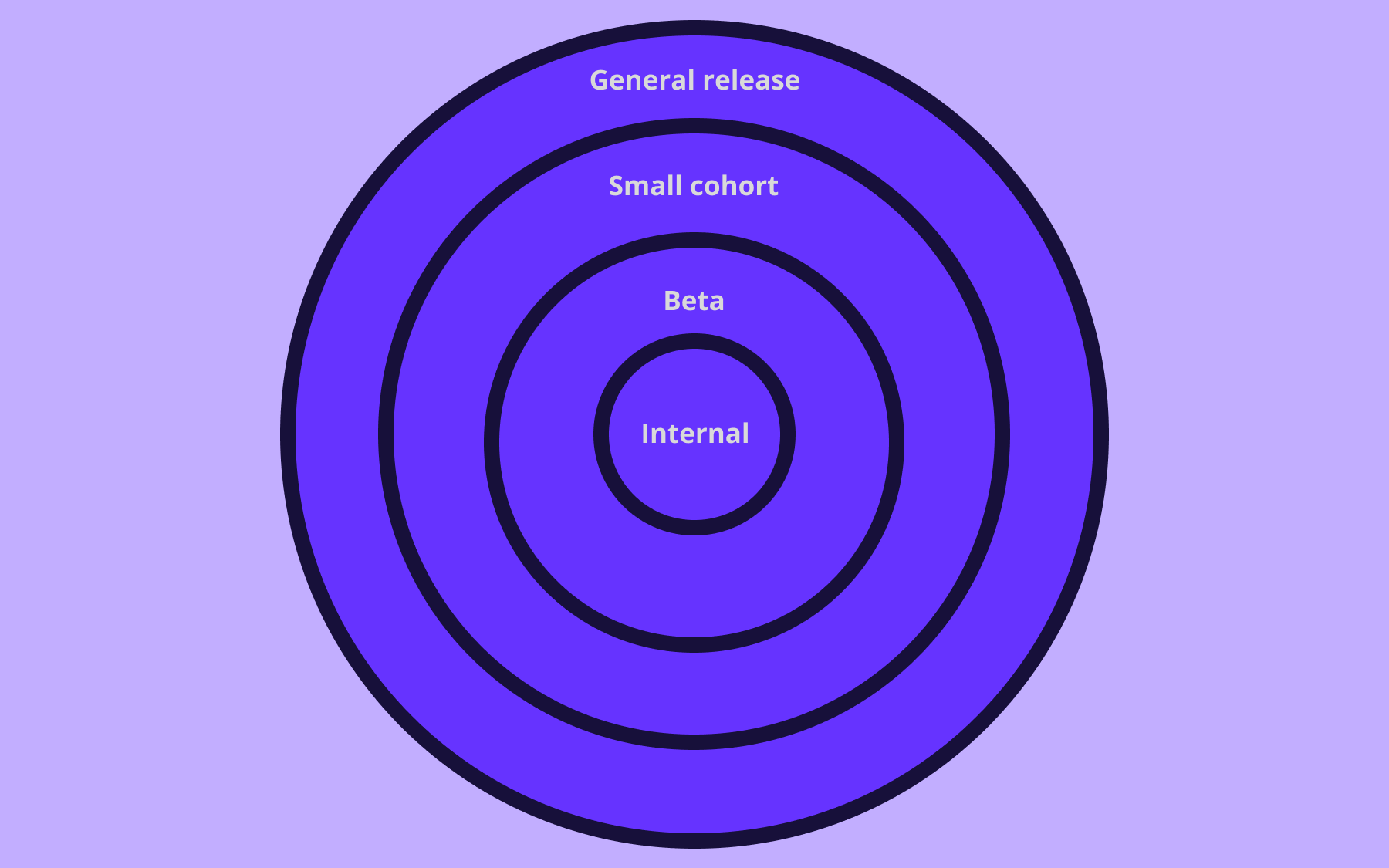
Once the new feature is code complete, it is ready for testing. At this point, since the team is practicing Continuous Deployment, the feature will already be live in both pre-production and production environments. That fact, plus feature flagging, allows testers to work in whatever environment makes sense, including the production environment, by enabling the feature only for internal users.
Once a feature has been validated, it can be released to users. What’s more, since it’s behind a feature flag, the team also has the option of doing things like canary release the feature to 5% of users, or A/B test the feature to see how it affects user behavior.
Showcases and feature releases
While features can be released one by one, as and when testing is completed, some Scrum teams opt to batch up their feature releases around their sprint cycle. This allows the team to showcase all the features that are to be released this sprint (they can also demo in production, if they want!). This also helps to reduce change fatigue from end users, since product changes occur on a predictable schedule.
Pitfalls to avoid
Teams making the journey towards Continuous Deployment face some bumps along the way. Let’s look at some potholes and how to avoid them.
Feature flags aren’t free
Feature flags are a powerful enabler of Continuous Deployment but they introduce clutter, each flag making code a little harder to read, test and modify. It’s important that teams establish best practices to manage “feature flag debt”, making sure to remove flags once the features they control are fully released.
Engineers also need to be sure that feature flags are implemented correctly, with half-finished code fully isolated when the flag is off. If this doesn’t happen when a team is practicing Continuous Deployment, there is a risk that un-tested code can be exposed in production. Careful, focused code review is important to mitigate this challenge, plus manual testing by engineers to validate the flag works as expected. A trustworthy suite of end-to-end tests for critical product flows provides additional protection.
Keeping track of what’s done
Feature flags provide an extra layer of control when it comes to release management, but that can also blur the lines around when a particular task is “done”. Teams may need to track additional information in their project management tool—you may want to track states like “merged”, “deployed to production”, “tested”, “experimenting”, or “fully released”. You should be careful to define clear unambiguous criteria for these states.
Continuous Deployment is achievable, with work
Accelerating toward Continuous Deployment delivers real value, but doing it successfully requires a big shift in how teams release features, moving from multi-day hardening phases to testing feature-flagged code after it’s live in production.
Continuous Deployment isn’t just about moving faster—it’s about building better. By shrinking batch sizes, teams make each deployment safer and easier to validate. Feature flags decouple deployment from release, letting work flow smoothly to production while still giving teams full control over when and how features are unveiled. Automated pipelines and smaller pull requests speed up feedback loops, helping developers catch issues earlier and focus on quality instead of overhead.
Add in the ability to experiment safely with real users, and Continuous Deployment becomes not only a way to ship code more often, but also a way to deliver more value, with less risk and greater stability.
I worked on an eBook with Flagsmith that might be useful to anyone reading this article. Check it out.



























OpenTelemetry, without the vendor lock-in: Introducing full observability for Open Source and Self-Hosted Flagsmith customers


































































.png)
.png)

.png)

.png)



.png)












.webp)