
When Canary Alerts Go Wrong: How We Fixed It and Doubled Down on OSS


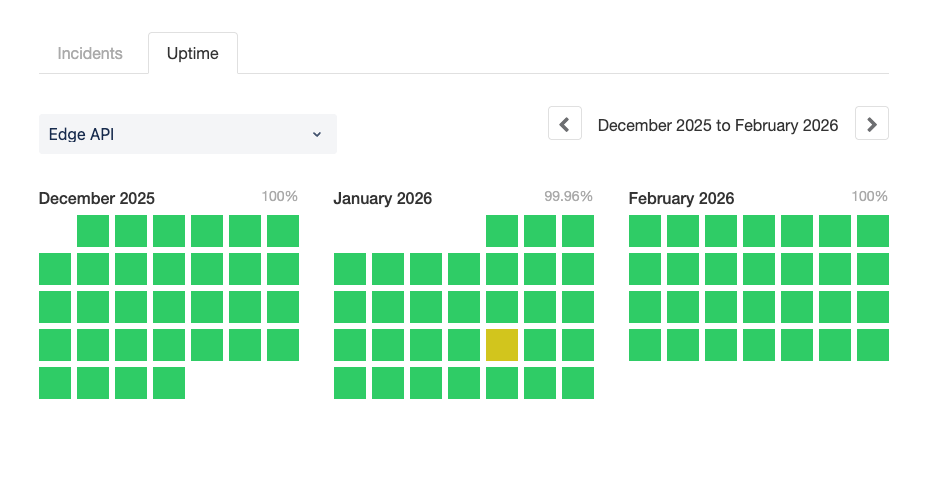
On 22 January 2026, Flagsmith's Edge API had its first blemish on what had been a 100% green uptime record.
This post is a public post-mortem, the story of how we responded, and came out of it with more open-source software in our toolchain than we went in with.
A bit of context first.
What is the Edge API?
Flagsmith's Edge API is a globally distributed, low-latency service that evaluates feature flags at the edge. At a high level, it is a collection of Python-based AWS Lambda functions deployed across eight regions, handling tens of millions of requests per day.
Uptime here is non-negotiable—this is the layer that Flagsmith customers depend on for remote flag evaluation, and any degradation has an immediate downstream effect.
Ever since Edge API’s inception in 2022, we have been relying on Serverless Framework to manage and deploy the Lambda handlers. It has worked well for us: since 2024, we have driven 731 successful deployments with Serverless. Extrapolated to 8 regions where our Lambda resides, that’s 5848 deployments across the board.
To ensure our 100% uptime, we employed AWS CodeDeploy with a canary strategy using a Serverless plugin; new code was gradually shifted from 0% to 100% of production traffic, with CloudWatch alarms acting as circuit breakers to trigger automatic rollbacks if something went wrong.
The goal was to catch problems early, with minimal blast radius, before they reached the full user base. We’d already seen the same principle work well in our own observability-driven feature flag rollouts, where a 10% release exposed issues before they could affect customers.
While that goal was sound, the implementation, as we found out, had a structural flaw.
The incident
Wave 1 – 21st January
We deployed Edge API v1.32.0 bearing a significant refactor of our evaluation engine. Within a few hours, a customer reported evaluation inconsistencies for identity overrides on multivariate features. We rolled back to v1.31.0 within two hours of the first report.
Wave 2 – 22 January
We shipped the fix. Twenty minutes later, CloudWatch alarms fired in ap-south-1. An unhandled type conversion error was causing 502s for a subset of environments. The status page moved to Partial Outage—the first time we'd seen anything other than green on the Edge API.
We deployed a second fix. This is the point when we hit a key issue.
Two regions—us-east-2 and us-west-1—rejected the deployment entirely. Their canary alarms were still in ALARM state from the previous version's errors. CodeDeploy sees an alarm in ALARM, refuses to proceed, and triggers a canary rollback. We were locked out of our own deployment pipeline.
What followed was about three hours of hands-on firefighting:
- Manually updating Lambda aliases
- Restarting rollbacks twice
- Resolving UPDATE_ROLLBACK_FAILED CloudFormation states across eight regions.
Not something you want to be doing under pressure, particularly when every minute of downtime has a real cost.
Why recovery was so painful
The bugs were fixable. What wasn't fixable at the moment of the outage was the structural problem underneath. There were four things working against us:
- Canary alarms weren't version-scoped
The alarms watched all traffic to the Lambda alias, meaning errors from the old version kept the alarm firing after we'd already rolled back. When we tried to deploy a hotfix, CodeDeploy saw those lingering alarms and refused.
We were locked out by our own circuit breaker.
- No emergency bypass
Every deployment went through the full canary process, including hotfixes. There was no way to skip it when speed was critical.
- Provisioned concurrency and canary don't play well together
During canary deployments, both the old and new versions need provisioned concurrency simultaneously. The handover is messy, and it compounds the other problems.
- Manual rollbacks across nine regions are brutal
When the automated process fails, you are console-hopping across regions, manually updating aliases and CloudFormation. It's exactly the kind of work that canary deployments are supposed to render obsolete.
The immediate fix: a bypass with skip CI in GitHub Actions
The day after the incident, we added a skip-canary CI option: a checkbox in the GitHub Actions workflow that bypasses canary entirely for hotfix deployments. Simple, but during an outage, the difference between a five-minute fix and a three-hour ordeal is exactly this kind of escape valve.
This was a first step to unlock potential further rollbacks as we prepared to tackle the underlying problem we discovered.
The real fix: version-scoped canary alarms
The Serverless plugin we were using to provision CodeDeploy configuration—serverless-plugin-canary-deployments, originally created by davidgf, hadn't had a commit to main in four years. Even though it was unsupported, it provided enough tooling to get by, and we'd learned to work around its limitations rather than fix them.
After the incident, that solution stopped being acceptable.
There was also a broader problem to reckon with. Serverless Framework v4, announced in October 2023, is no longer open source—it moved to a proprietary licence with pricing fees for organisations above the $2M annual revenue threshold.
We'd been running on v3, which is no longer officially maintained. A full migration to AWS CDK, AWS SAM, or another tool would have meant rewriting our entire deployment harness for the Edge API. It was clear that a significant investment would have delivered no direct value to our users.
Instead, we doubled down. We forked the plugin, rebuilt its core alarm logic, and switched our framework dependency to osls (previously known as oss-serverless)—a community-maintained fork that keeps the Serverless Framework open and free.
As the original vendor moved to a closed model, we doubled down in the opposite direction: open source.
Fixing the alarms
The fix was to create alarms scoped specifically to the version being deployed, using the ExecutedVersion dimension. Old errors become invisible to the canary. The circuit breaker only fires for problems in the code you're actually deploying.
What the new plugin does
The plugin added version-specific CloudWatch alarms with a few useful features:
- canaryAlarms configuration – Alarms scoped to the deploying Lambda version, with a built-in errors preset for the common case and full customisation for metrics like Duration
- Composite alarm – An auto-generated stack-level alarm (${service}-${stage}-canary-composite) that fires if any function's canary alarm triggers—useful for cross-region orchestration
- IAM permissions documentation – A full list of all required permissions, which was previously left as an exercise for the reader
A minimal configuration looks like this:
functions:
hello:
handler: handler.hello
deploymentSettings:
type: Canary10Percent5Minutes
alias: Live
canaryAlarms:
type: errors # Built-in preset
- metric: Duration
threshold: 5000 # Custom metric
comparisonOperator: GreaterThanThreshold
Developing with Claude and the AWS CLI
We used Claude Code with read-only AWS CLI access to build and test the plugin. The feedback loop was remarkably tight.
The cycle was:
- Claude generates CloudFormation template changes
- Trigger deploy to staging with GitHub CLI
- Claude reads AWS CloudWatch alarm states via describe-alarms
- Claude reads CloudFormation stack events
- Iterate.
For a plugin that generates complex CloudFormation resources, this cycle was significantly faster than the alternative, which would have required a lot of manual console navigation across regions. The decision to give the AI tool live cloud infrastructure feedback made it genuinely effective for this kind of work.
What production has taught us
We released plugin v1.0.0 to npm on 5th February and deployed it to production the following day.
The first production deployment rolled back—the Duration canary alarm caught the bulk_identities and bulk_identify functions exceeding 1,000ms. This was a reasonable threshold in theory, but those functions are batch operations that are always slow. We introduced two latency tiers with different thresholds.
Cold starts triggered alarms, too. Since canary alarms only watch the new version, and the new version starts with zero provisioned concurrency, every invocation is a cold start. We bumped the thresholds and datapointsToAlarm to tolerate cold-start latency.
The real-world latency data from production in March 2026 illustrates why blanket alarm thresholds don't work across regions:
Seoul runs nearly four times slower than Sydney. A single alarm threshold that works for one will either never fire in the other, or fire constantly.
What's next: SLOs and metric math alarms
We've already merged metric math alarm support into the plugin fork, though we haven't fully used it in production yet.
We're in the process of defining proper SLOs for our stack, starting with the Edge API, and the regional latency variance means we can't use a single alarm expression across all regions and functions.
Metric Math lets us define things like P99 latency thresholds and relative increases—something like, "error rate increased by more than X% in the last 15 minutes"—rather than absolute values that may only be appropriate for one traffic tier.
The goal is to have canary alarms based directly on our SLOs, per region, potentially bucketed into traffic-volume tiers: low, medium, and high for traffic patterns.
Watch this space!
Why this matters
The incident on 22 January exposed something we'd been carrying for a while: a canary deployment setup that worked well enough under normal conditions but had a structural flaw. Even worse, it only became apparent to our team under pressure.
The fix required us to go deeper than a quick patch. We had to actually rebuild the alarm logic in a way that eliminates the problem at its source.
We chose not to take the path of least resistance. Serverless going proprietary would have eventually forced a costly rewrite anyway.
Instead, we switched to the community fork, built and published a better plugin, and sponsor the maintainers of osls—we depend on it for production infrastructure and shouldn't take that for granted.
The osls project is maintained by a small community, and we know we can't rely on it indefinitely, but by raising awareness and contributing back, we hope to bring more support to the project. That's the thing about open source: it doesn't solve problems forever, but it gives you options, and it rewards the people who invest in it.
The plugin is on npm and the serverless-plugin-canary-deployments fork is on GitHub, so take a look.






















OpenTelemetry, without the vendor lock-in: Introducing full observability for Open Source and Self-Hosted Flagsmith customers



































































.png)
.png)

.png)

.png)



.png)

















.webp)