
Deployment Frequency: The Metric That Reveals How Fast Your Team Really Ships


Deployment frequency is one of those metrics that sounds straightforward on the surface—count how many times your team deploys, done—but it tells a much richer story than that.
How often an engineering team successfully deploys to production reflects its culture, its processes, how it manages technical debt, and the choices it's made about tooling—It’s a proxy for confidence.
And yet, according to the 2025 DORA report, which surveyed nearly 5,000 technology professionals, only 16.2% of organisations achieve on-demand deployment, meaning multiple times per day. The vast majority of teams cluster somewhere between once a week and once a month. High deployment frequency is achievable. It's just far from the default.
The gap between where most teams sit and where they could be isn't usually a talent problem. It's a process problem. Teams want to ship more often, but they're blocked by large release batches, slow feedback loops, and the fear of pushing incomplete or unstable work into production before it's ready.
This article addresses all of it: what deployment frequency actually measures, how to benchmark and track it, what holds teams back, and, critically, how to remove those blockers in practice.
What is deployment frequency?
Deployment frequency measures how often code is successfully deployed to a production environment. It is one of the four core DORA metrics. These metrics are:
- Deployment frequency (DF)
- Lead time for changes (LT)
- Change failure rate (CFR)
- Failed deployment recovery time or mean time to restore (MTTR)
Together, these metrics give engineering leaders a clear picture of software delivery performance—both how fast code moves and how stable it is when it gets there.
One distinction is worth establishing early: deployment is not the same as release. Deploying code means pushing it to production. Releasing means making it visible or available to users. With the right tooling, you should be able to decouple deployment from release, so they happen independently of each other.
This separation is central to how high-performing teams increase their deployment frequency without increasing their risk.
Deployment frequency as a DORA metric
DORA (DevOps Research and Assessment) has been running its research programme for over a decade, initially as an independent study and now under Google.
The foundational work is captured in the book Accelerate by Nicole Forsgren, Jez Humble, and Gene Kim, which established that deployment frequency is one of the strongest predictors of overall organisational performance—not just delivery speed, but commercial outcomes too.
The 2025 DORA report surveyed 4,867 technology professionals and shifted its primary focus to AI-assisted software development. It replaced the traditional elite/high/medium/low performance tier model with seven distinct team profiles. The four core metrics around deployment and the production environment, however, remain the foundation of the framework.
Deployment frequency benchmarks
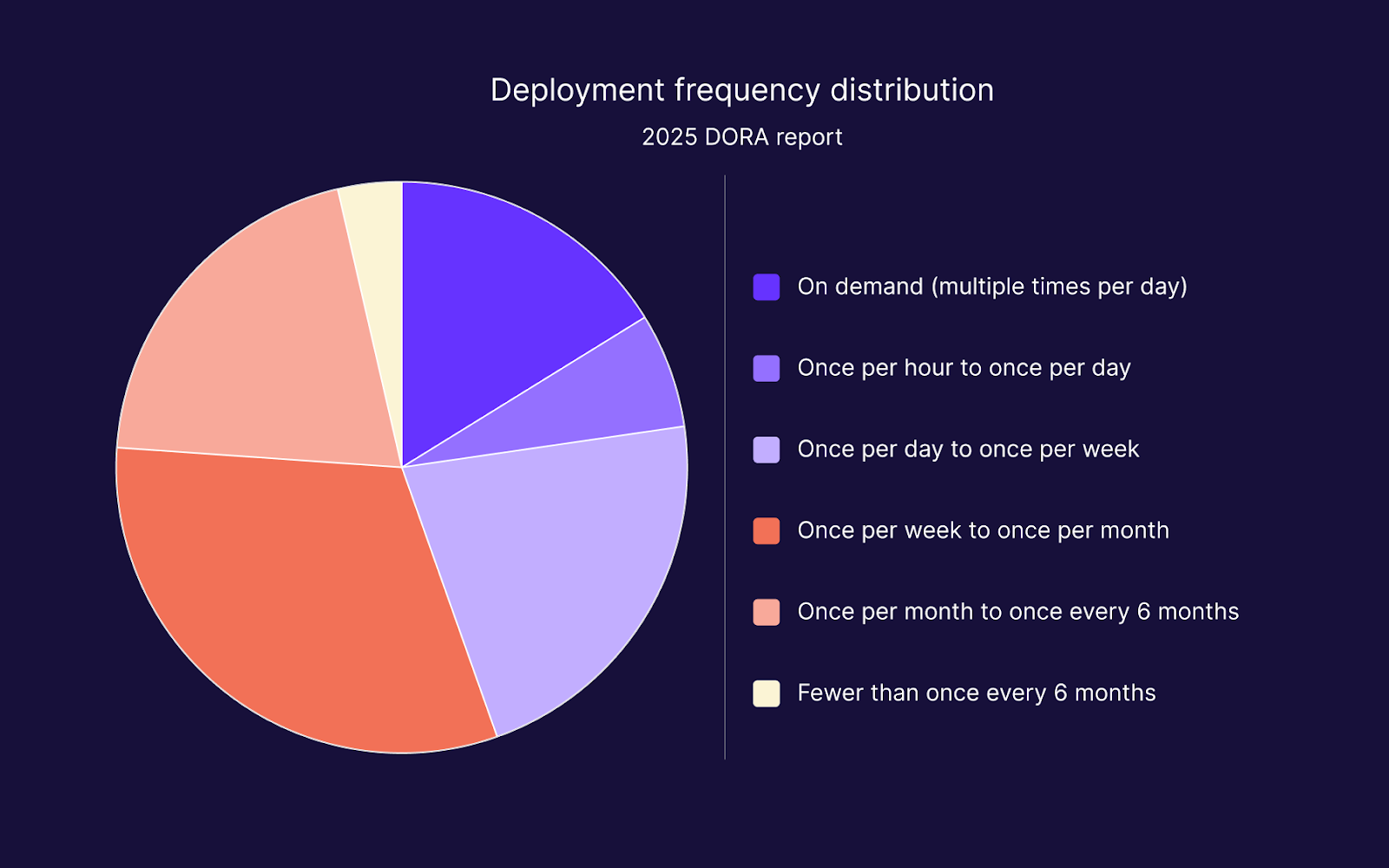
Rather than grouping teams into abstract performance tiers, the 2025 DORA report presents a full distribution of where organisations actually sit. It's more useful than labelled categories because it shows, concretely, where most teams land (rounded up):
- 16.2% deploy on demand, multiple times per day
- 6.5% deploy between once per hour and once per day
- 21.9% deploy between once per day and once per week
- 31.5% deploy between once per week and once per month (the single largest group)
- 20.3% deploy between once per month and once every six months
- 3.6% deploy fewer than once every six months
The headline: 23.9% of teams deploy less than once a month, and the largest cluster sits in the once-per-week to once-per-month band. If your team is in that range, you have a great deal of company and a clear direction for improvement.
How to measure deployment frequency
Understanding the benchmark is useful, but it's only actionable once you know how to measure deployment frequency consistently for your own team. The good news is that there's no complex formula here.
To calculate deployment frequency, count successful production deployments over a defined time period—whether that's per day, per week, or per month. The key is agreeing on what counts as a deployment and sticking to that definition.
Two practical approaches are most common:
- Manual tracking—pulling deployment logs from your CI/CD (continuous integration / continuous deployment) pipeline or delivery dashboard and counting successful runs to production. Most CI/CD tools surface this directly.
- Automated tooling—DORA provides a self-assessment through its Quick Check tool that gives teams a baseline measure without needing to instrument anything.
A note on misleading signals: a very high deployment frequency isn't automatically a healthy sign. If your count is inflated by broken-up hotfixes or emergency patches, that's worth validating against your change failure rate. The deployment frequency metric is most informative when read alongside the other DORA metrics, not in isolation.
What slows deployment frequency down?
With a clear picture of how to measure deployment frequency, the obvious next question to ask is, why don't more teams deploy more often? There are a handful of recurring blockers, and most of them compound each other.
Large batch sizes
When teams bundle many changes into a single release, they create deployments that are large, risky, and slow to validate. The more code in a single batch, the more testing it needs, the more sign-off it requires, and the harder it is to trace a bug back to its source if something goes wrong.
Batch size and deployment frequency are inversely related: the bigger the batch, the less often it ships.
Long-lived feature branches
Branches that run for days or weeks accumulate divergence from the main codebase. By the time they're ready to merge, integration conflicts are almost inevitable, and resolving them takes time that could have been spent shipping.
Long-lived branches are one of the most common causes of delayed deployments in teams that otherwise have good intentions about shipping frequently. It's a problem that trunk-based development addresses directly.
Slow or manual pipelines
Every manual step in a deployment pipeline is a speed tax. Slow test suites, manual approval gates, and fragile build processes all add friction between code being written and code reaching production.
DORA's research consistently identifies CI/CD automation as a shared capability among high-performing teams, and it's not incidental.
Fear of releasing incomplete work
This one often goes underappreciated.
Engineers delay deployments not because the code is broken, but because the feature isn't ready for users to see. The code is stable enough to ship; it just isn't polished enough to release. Without a way to separate these two decisions, the deployment waits for the feature, and features rarely land on a convenient schedule.
How to improve deployment frequency
Addressing those blockers isn't a single fix, it's a set of practices that reinforce each other.
The teams that improve their deployment frequency tend to do several of these things in parallel rather than treating them as a sequential checklist.
Work in smaller batches
Smaller commits, smaller pull requests, fewer changes per deployment. It sounds obvious, but the discipline required to actually work this way is significant.
Smaller batches mean lower risk per deployment, faster code review, easier rollbacks, and a tighter feedback loop with production. Frequency tends to increase naturally as batch size comes down.
Invest in CI/CD automation
Removing toil from the deployment process is one of the most reliable ways to increase how often a team deploys. When automated testing, linting, and deployment pipelines handle the manual overhead, the decision to ship becomes easier and faster.
DORA research consistently identifies CI/CD practices as a capability shared by higher-performing teams—not because automation is the goal, but because it removes the friction that prevents more frequent deployments.
Adopt trunk-based development
Trunk-based development is a practice where all developers commit to a single main branch frequently, at least once per day, rather than maintaining long-lived feature branches. It keeps integration costs low, ensures the codebase is always close to a deployable state, and naturally encourages the small-batch discipline described above. It's a meaningful mindset shift, and it works best alongside automated testing and feature flags.
Feature flags and deployment frequency
The practices above reduce the friction around deployment. Feature flags address a different problem: the fear of deploying code when the feature it contains isn't ready for users. This fear is one of the primary reasons teams delay pushing to production, even when the code is stable.
Feature flags decouple deployment from release. When a feature is wrapped in a flag, it can be deployed to production at any time—the flag simply keeps it invisible or inactive for users until you're ready. The deployment and the release become two separate decisions made at two separate times.
That single change removes the most common psychological barrier to more frequent deployments. Below are three ways feature flags can help improve deployment frequency without introducing extra risk.
- Decouple deployment from release
In practice, this means an engineer can merge a feature that's 80% done, deploy it to production behind a flag, and continue iterating—all without any user impact.
The codebase stays current, the branch stays short-lived, and the deployment happens on the engineering team's schedule rather than waiting for the feature to reach some subjective threshold of readiness.
This lever is one of the most direct ways to increase deployment frequency in teams that are blocked by incomplete features rather than technical problems.
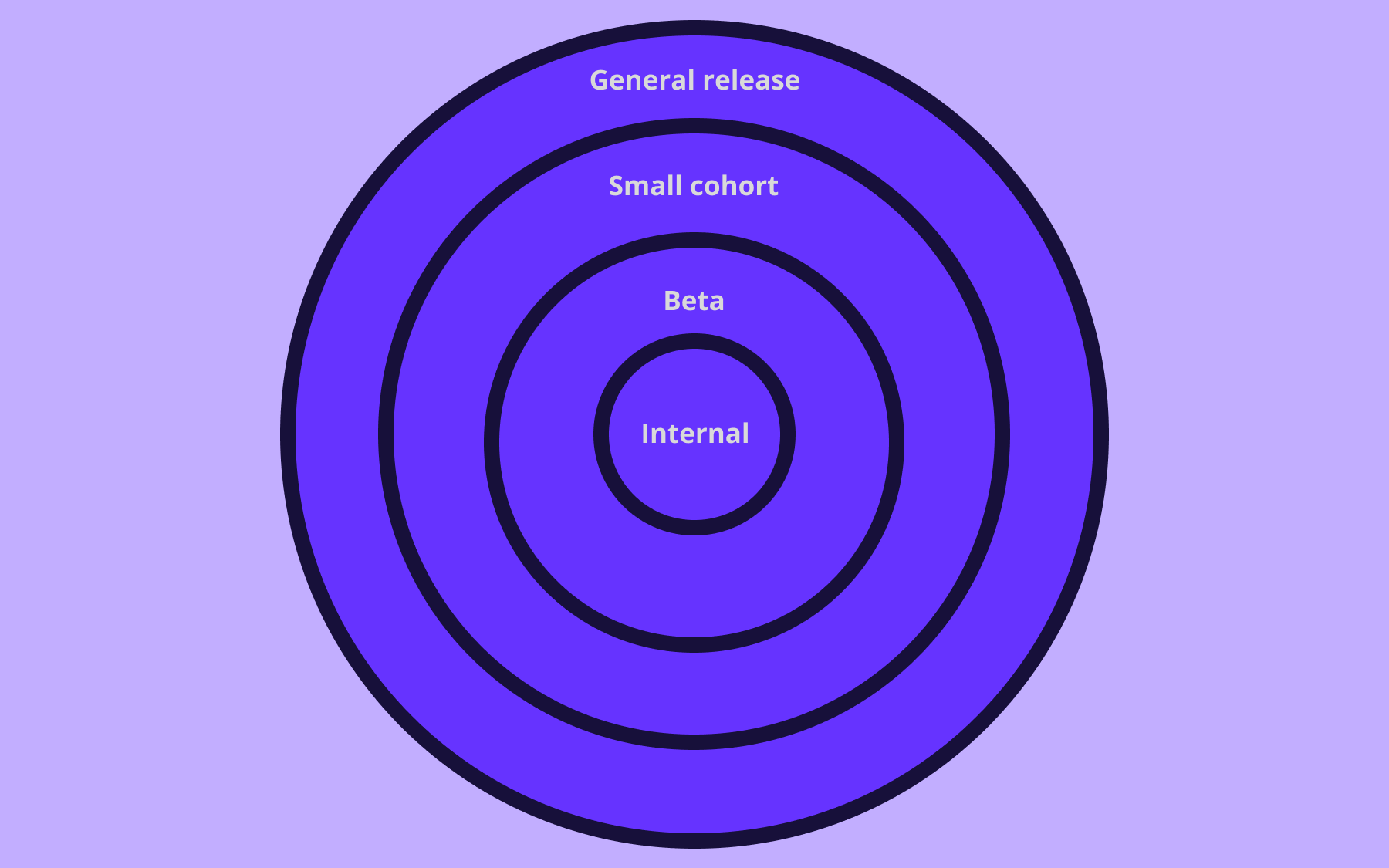
- Progressive rollouts and canary releases
Feature flags don't just control whether a feature is on or off, they also let you control who sees it. Canary releases expose a new feature to a small percentage of users first: 1%, then 5%, then 50%, then 100%, which reduces the blast radius of any given release and allows teams to gather real user feedback before committing to a full rollout.
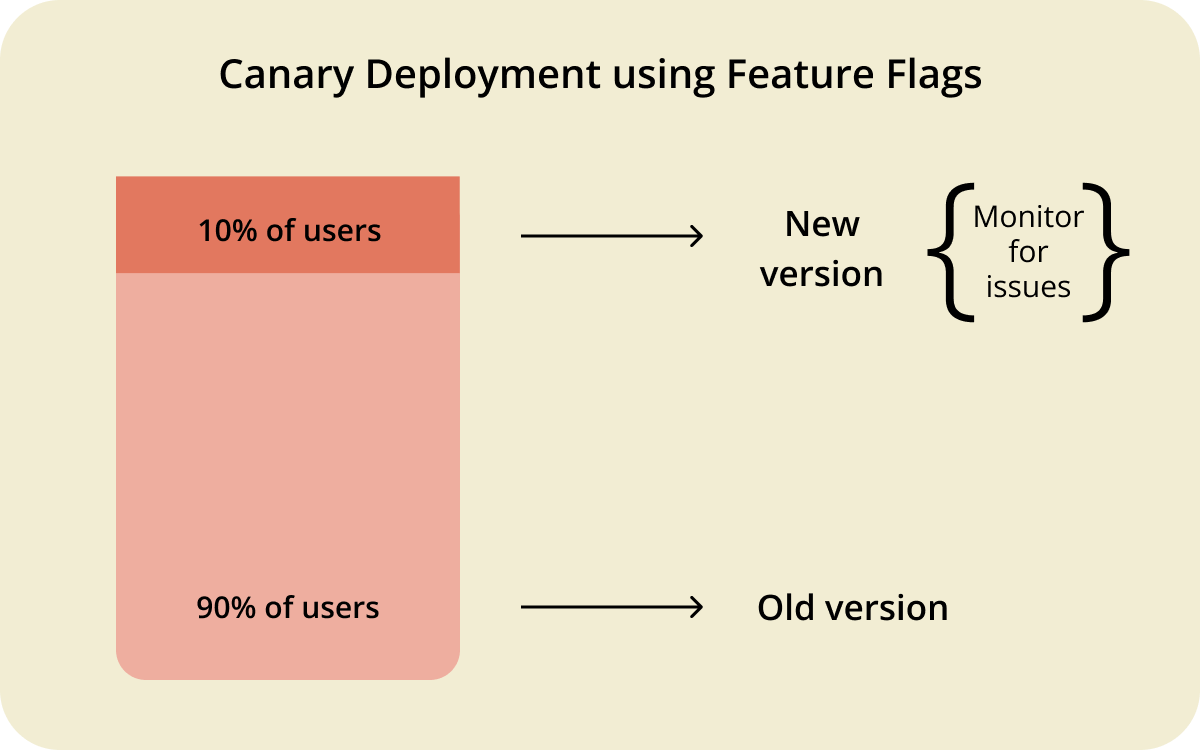
Deploying more frequently becomes less risky when each individual deployment touches fewer users and can be walked back in seconds. Engineering leaders scaling these practices across multiple teams will find the patterns described in this guide to scaling feature flags worth reading.
- Instant rollbacks without a redeployment
One of the most practically valuable aspects of flag-based releases is the rollback story. If a feature causes problems in production, turning off the flag is faster and safer than reverting a commit and redeploying. No new build, no new deployment pipeline run, no coordination with the rest of the team. The change takes effect immediately. This adjustment lowers the cost of a bad deployment significantly, and when the cost of a bad deployment is low, teams are less hesitant to deploy in the first place.
It's a compounding effect: each improvement in rollback confidence leads to more frequent deployments, which leads to smaller batches, which leads to fewer bad deployments.
Tracking Deployment Frequency Over Time
Once the practices above are in place, deployment frequency becomes a metric worth watching consistently rather than measuring once and moving on. What to track is straightforward: the number of successful deployments per day or week, broken down by service or team if your architecture warrants it.
The more important habit is reading it alongside change failure rate.
- A rising deployment frequency with a stable or improving failure rate is a healthy signal: teams are shipping more and the quality is holding.
- A rising frequency paired with a rising failure rate is a warning sign: the deployment process has sped up, but something upstream hasn't kept pace.
This context makes deployment frequency a genuinely useful metric rather than a number to optimise in isolation.
DORA's Quick Check tool is a useful starting point for teams that haven't benchmarked themselves before. It gives a fast, self-reported read on where you sit across all five DORA metrics and offers a direction for improvement based on where the gaps are.
For teams that want to go deeper, the research behind the metrics—summarised in Accelerate by Forsgren, Humble, and Kim—provides the evidence base behind each capability.
Ship More, Risk Less
Deployment frequency is not a count of how often code ships; it’s a measure of how well a team has removed the friction, fear, and overhead that prevent code from shipping.
The teams that deploy most often aren't necessarily working harder, they've usually just made a series of deliberate choices that compound over time: smaller batches, automated pipelines, trunk-based development, and feature flags that let them separate deployment from release.
Each of those levers helps independently. Together, they make frequent deployment not just possible but sustainable—they make it safer, not riskier.
If your team is running a deployment strategy where you’re in that 31.5% deploying once a week to once a month, the path forward is rarely a single fix. But it almost always involves changing the relationship between deployment and release. That's where Flagsmith comes in. Start for free and see how feature flags change what's possible for your deployment process.

























OpenTelemetry, without the vendor lock-in: Introducing full observability for Open Source and Self-Hosted Flagsmith customers




































































.png)
.png)

.png)

.png)



.png)












.webp)