
The Benefits of A/B Testing, and Why Feature Flags Make It Even Better


Are your company's product decisions still made on gut feel? For example, a senior stakeholder prefers one version of a new workflow, a product manager believes a redesigned onboarding step will improve activation, or an engineering team ships a new feature interaction because it seems more intuitive.
Sometimes those instincts are right. Often, they're not. The problem is that the cost of being wrong compounds across every release, especially when a change reaches every user at once.
A/B testing replaces opinion with evidence. Instead of debating which new version users might prefer, teams can run tests, collect data, and measure how users interact with different versions of a feature, page, or experience. What started as a digital marketing technique for testing landing pages, email subject lines, and ad creatives now sits much closer to the centre of modern product development.
However, the benefits of A/B testing are only fully realised when teams have the right infrastructure underneath them. It's one thing to design a good experiment; it's another to target the right user groups, control exposure, monitor key metrics, and roll back a poor-performing variation instantly.
Feature flags change that equation.
What is A/B testing?
A/B testing, also called split testing, is the practice of showing different variations of a feature, web page, message, or experience to different user groups, then measuring which version performs better against a defined metric.
The “A” version is usually the current experience, while the “B” version is the new variation. In some cases, teams test more than two variants through A/B/n or multivariate testing. The goal is to understand whether a change has a measurable effect on business outcomes such as conversion rates, click-through rates, customer retention, user engagement, bounce rates, or marketing ROI.
A/B testing applies across many development workflows and outcomes, for example:
- Product features
- Onboarding flows
- Pricing experiments
- E-commerce experience improvements
- Page layouts
- Checkout journeys
- Subject line tests
It's not limited to changing only one element on a website button, although isolating one variable can make it easier to interpret test results. The shared principle is always the same: compare different versions, gather sufficient data, and use statistical analysis to inform decisions.
The core benefits of A/B testing
The biggest A/B testing benefits are all interlinked. Better decision-making reduces release risk. Lower risk encourages more experimentation. More experimentation produces valuable insights about user behaviour, which leads to continuous optimisation over time.
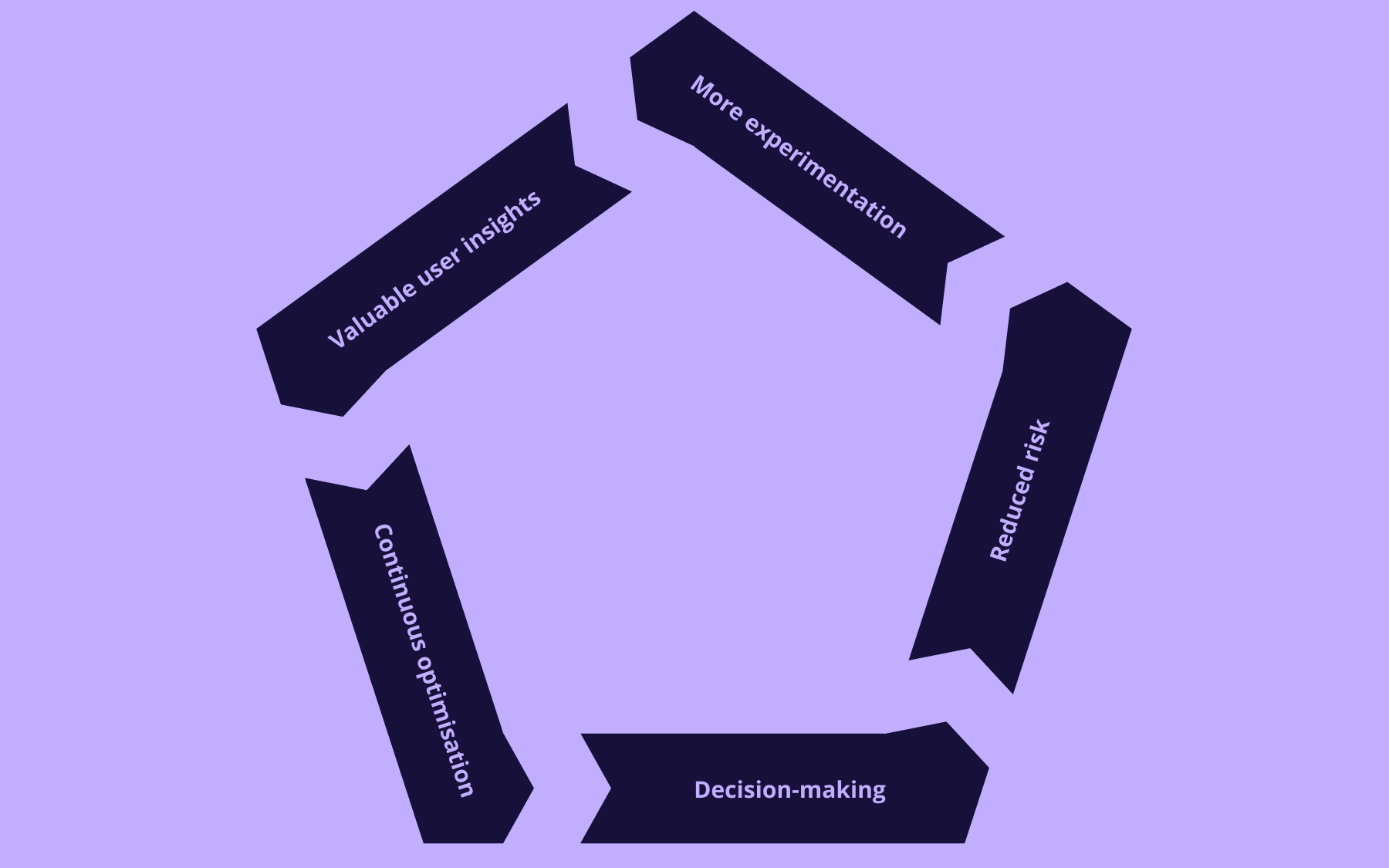
Harvard Business School Working Knowledge covered research analysing 35,262 high-tech startups and found that firms adopting A/B testing had stronger outcomes across measures such as weekly page views, likelihood of raising venture funding, and product launches.
The article reported that startups adopting A/B testing technology had roughly 10% more weekly page views, were 5% more likely to raise venture capital, and launched 9% to 18% more products.
Ron Kohavi and Stefan Thomke have also documented the scale of experimentation at major technology companies. In their HBR article, they note that Microsoft, Amazon, Booking.com, Facebook, and Google each conduct more than 10,000 online controlled experiments annually, often involving millions of users.
Decisions backed by data, not instinct
The most obvious benefit of A/B testing is also the most important: it moves decision-making away from instinct and toward evidence.
Without A/B testing, teams often choose between different variations based on seniority, personal preference, or the loudest opinion in the room. That can work for low-stakes creative choices, but it breaks down when teams are making product decisions with a significant impact on revenue, retention, or user experience.
A/B testing gives teams actionable insights from real user interactions. Instead of asking whether a target audience will respond better to one call to action or another, teams can test variations against existing traffic and see which version performs better. Instead of assuming a new feature will drive more engagement, they can measure engagement metrics and learn from actual behaviour.
After all, many ideas that look good on paper don't work in practice.
Kohavi and his co-authors have written that at Google, LinkedIn, and Microsoft, about two-thirds of experiments failed to improve the metrics they were designed to change. In highly optimised areas such as search engines, failure rates were even higher.
We're not making an argument against testing. In fact, it's the strongest argument for it.
If only around one in three ideas produces a statistically significant positive result, shipping without testing means teams are effectively choosing randomly between outcomes they could have measured. A/B experiments are the layer of protection, which leads us nicely onto the next benefit.
Reduced risk on every release
One of the most commercially significant benefits of A/B testing is risk reduction.
When a team releases a major change to 100% of users, any negative impact hits the full customer base immediately. A broken flow, confusing new interface, slower page, or poorly performing variation can affect conversion rates, support volume, revenue, and customer retention before the team has enough data to react.
A/B testing changes that pattern. Teams can expose a new version to a small percentage of users, monitor key metrics, and increase traffic volume only when the data supports it. If a bad variant affects 5% of users instead of 100%, the downside is contained.
This incremental exposure is especially valuable for teams shipping frequently. Product and engineering teams can validate major changes in production without treating every release as an all-or-nothing decision. They can compare test variations, monitor for statistically significant results, and stop a poor-performing version before the effect compounds.
In practice, this makes experimentation feel safer. Teams are more willing to test new product features, onboarding steps, pricing changes, and page layouts when they know a losing variation will not automatically become every user's experience.
Continuous improvement to conversion and retention
A/B testing is often associated with conversion rates, but it has a broader value than a single lift in one metric. The real benefit comes from continuous testing.
A single test might identify a better landing page headline, a clearer checkout step, or a new version of an onboarding screen that creates more engagement. But the larger value comes from repeating that process across various aspects of the product and customer journey.
Small improvements can accumulate. A modest increase in sign-ups, a small reduction in bounce rates, a better activation flow, or a slight improvement in customer retention may not look like a huge change in isolation. Over time, these gains can have a meaningful effect on business outcomes.
It's no surprise, then, that companies such as Booking.com and Netflix are often discussed in the context of high-volume experimentation.
At scale, teams aren't betting everything on one test; they're building systems that let them run tests continuously, learn quickly, and compound incremental gains across the funnel.
Kohavi and co-authors describe major technology companies, including Netflix, as running online experiments at scale, with hundreds of concurrent controlled experiments on millions of users.
You can see how experimentation grew over time at these large companies in this chart.
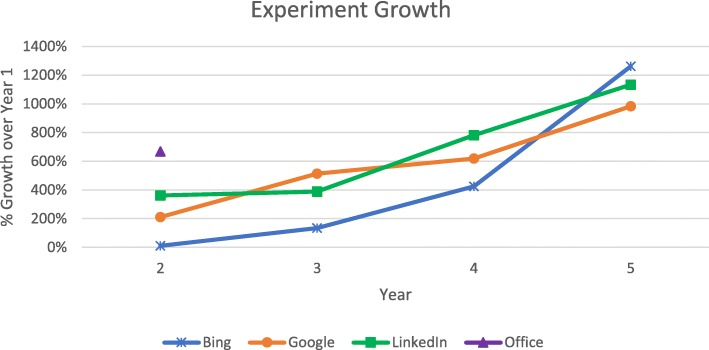
As well as higher conversion, a key benefit is the normalisation of data-driven optimisation.
Faster, more confident learning cycles
A/B testing also creates organisational learning.
Each experiment gives teams qualitative data, quantitative data, or both. A winning variation shows what users respond to and what will maximise ROI. A losing variation shows what they don't respond to. An inconclusive result can be just as useful if it prevents a team from over-investing in a change that has no meaningful results.
Over time, this creates a clearer picture of user preferences, market trends, and the kinds of product changes that actually move key metrics. Teams stop treating experiments as isolated events and start treating them as a learning system.
This is a culture-level benefit. Instead of asking, “Who has the best idea?” teams ask, “What hypothesis are we testing, and what would we need to see to act on it?” That shift supports better marketing strategies, better product roadmaps, and more confident prioritisation.
Rather than completely removing judgement from product development, embracing experimentation improves judgement by grounding it in evidence.
Feature flag vs. A/B testing: There's no comparison
The feature flag vs A/B testing question comes up often, but the two are not competing approaches.
A feature flag is a delivery mechanism. It lets a team turn functionality on or off, serve different experiences to specific user groups, or control access to a product feature without deploying new code.
An A/B test is a measurement methodology. It starts with a hypothesis, defines a success metric, splits users between different versions, and uses statistical analysis to determine whether one version performs better.
In other words, a feature flag can help deliver the different variations used in an A/B test. The A/B test measures the outcome.
Feature flags can also be used with no experimentation intent at all.
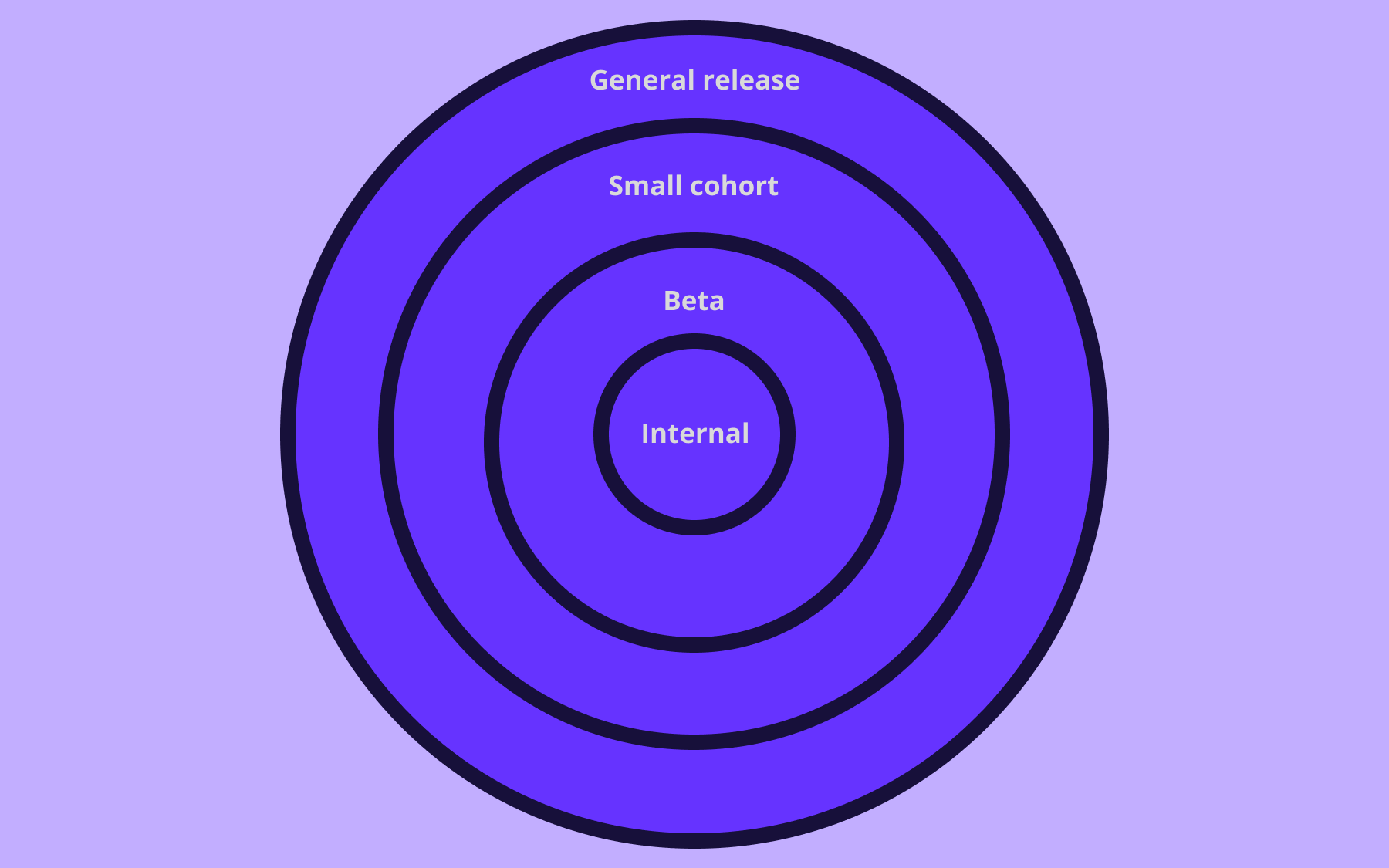
Teams use them for controlled rollouts, beta access, kill switches, entitlement management, operational safeguards, and remote config. A flag might turn on a new feature for internal users, a specific customer segment, or 10% of traffic without measuring a conversion goal.
A/B tests, by contrast, require more than traffic splitting. They need a hypothesis, a sample size large enough to produce meaningful results, a defined metric, and a way to determine statistical significance. They also need consistent bucketing so that the same user keeps seeing the same variation.
So the answer to feature flag vs A/B testing is usually: you need both. The feature flag controls who sees what, while the A/B test tells you whether that experience improved the metric that matters.
How feature flags unlock A/B testing benefits
Successful A/B testing depends on speed, control, and trust. Teams need to create test variations quickly, target the right audience, collect data from real user behaviour, and act on test results without waiting for another deployment cycle.
Flagsmith is an open-source feature flag and remote config platform that supports this kind of workflow. In Flagsmith, A/B testing uses multivariate flags with a third-party analytics platform, where the flag acts as the bucketing engine and the analytics platform receives event data based on user behaviour.
Product and engineering teams can use feature flags to control the experience, while continuing to analyse results in the analytics, observability, or data warehouse tools they already trust.
Precise user targeting for cleaner experiments
Not every A/B test should run across the entire user base. Sometimes the target audience is users in a specific location, customers on a certain plan tier, visitors using a particular device type, or accounts with a particular usage pattern.
Precise targeting helps create cleaner experiments, for example:
- If a test is designed for enterprise admins, including users on your free plan may dilute the results
- If a test is designed for mobile onboarding, desktop users may add noise
- If a pricing experiment is relevant only to a specific market, a global random split may produce misleading results.
Flagsmith segments are defined by rules that match identity traits, and segment overrides can control feature behaviour for identities in a specific segment. Teams can also use Flagsmith's segments to force user groups into a specific A/B test variation by overriding multivariate flag weightings.
Teams can define targeting rules directly on the flag, so the experiment runs on the population it was designed for.
Instant rollback without a deployment
One of the most practical A/B testing benefits of feature flags is instant rollback.
If a test variation causes a problem, the team shouldn't need to write new code, wait for CI, deploy again, and hope the rollback reaches users quickly. The safer pattern is to disable the variation at the flag level.
This functionality is especially important when teams run tests in production. A variation might hurt conversion rates, introduce an edge-case bug, increase latency, or create confusion for a specific user group. With a feature flag, teams can turn off the variant while leaving the rest of the release intact.
Flagsmith's multivariate flags enable teams to define multiple variants with percentage weightings, and the SDK returns the flag state and value that application code uses to drive experiment behaviour. Because the variation is controlled by the flag, teams can change exposure without another deployment.
The perceived risk of experimentation is lowered, and when rollback is fast, teams can test more often.
Testing in production safely
Staging environments are useful, but they rarely reflect production accurately enough to produce trustworthy experiment data. They don't contain real traffic patterns, real user preferences, real device variation, or real-world usage intensity.
Feature flags let teams test in production while limiting exposure – they can also decouple deployment from release. A team can release dormant code, enable it for a small segment, monitor user interactions, and expand only when the results justify it.
Flagsmith's A/B testing enables a scenario where most users are excluded from a test, while smaller user groups are bucketed into control and treatment variations. Users get consistent identities for reliable bucketing, including persistent anonymous IDs for unknown users.
Teams get data from real users, but they do not have to expose every user to the new experience at once – this is what makes production experimentation practical.
What to look for in a feature flag tool for A/B testing
Teams searching for the best feature flag tools for A/B testing in 2026 should look beyond a simple on/off toggle.
Here are the key features to opt for in an A/B testing feature management platform:
- Multivariate testing support. A good tool should support different variations, percentage weightings, and consistent user bucketing so that users do not jump between experiences mid-test.
- User targeting and segmentation. Teams should be able to run experiments for specific user groups based on traits such as plan, role, geography, device, account type, or lifecycle stage – essential for cleaner experiments and more actionable insights.
- Analytics integration. Some teams want statistical significance tracking inside a dedicated experimentation platform. Others prefer to send flag data into tools such as Amplitude, Mixpanel, Grafana, or a data warehouse, then analyse results alongside existing product, marketing, and observability data. Use Flagsmith for bucketing and send event data to an analytics platform.
- Compliance controls. Audit logging, role-based access, approval workflows, and clear change history become important as experimentation moves from occasional marketing activity to core product infrastructure.
- Deployment model. Open-source and self-hosted feature flag tools give teams more control over data residency, which can matter for regulated industries or teams handling sensitive user data. Data sovereignty is a key reason to keep feature flag data within your own infrastructure.
Flagsmith is one example of a tool that fits this model: open-source, built around feature flags and remote config, able to support A/B/n testing through multivariate flags, and designed to integrate with the analytics stack teams already use.
Start testing with confidence
A/B testing is one of the highest-leverage practices available to product and engineering teams. It helps teams replace opinion with evidence, reduce release risk, improve user experience, and build a culture of continuous optimisation.
But the value of A/B testing depends on the infrastructure supporting it. Without controlled rollout, targeting, consistent bucketing, and fast rollback, experiments become slow to set up and risky to run.
Feature flags provide that infrastructure. They make tests faster to launch, safer to expose, and easier to act on once the data comes in.
To run A/B tests without the usual deployment overhead, get started with Flagsmith and use feature flags to target variations, measure results, and roll back instantly when needed. Sign up for free to start using Flagsmith, or contact us for more information.
Benefits of A/B Testing FAQs
What are the main benefits of A/B testing for product teams?
The main benefits of A/B testing are better decision-making, reduced release risk, improved conversion rates, stronger customer retention, and faster learning cycles. Product teams can test variations with real users, collect data, and use statistically significant results to inform decisions instead of relying on assumptions.
How long should an A/B test run before you can trust the results?
An A/B test should run long enough to collect sufficient data for the metric being measured. The right duration depends on sample size, traffic volume, expected effect size, and the level of statistical significance required. Teams should avoid ending one test early just because the first results look promising, as early fluctuations can be misleading.
Do you need a dedicated experimentation platform to run A/B tests?
Not always. Some teams use a dedicated experimentation platform, while others combine a feature flag tool with their existing analytics stack. The key requirements are consistent bucketing, clean targeting, reliable event tracking, and statistical analysis. For many product teams, feature flags plus existing analytics tools are enough to run meaningful A/B tests.
























OpenTelemetry, without the vendor lock-in: Introducing full observability for Open Source and Self-Hosted Flagsmith customers




































































.png)
.png)

.png)

.png)



.png)












.webp)