
Feature Flag Testing: How Enterprise Teams Build Real Product Learning Loops


Every quarter, somewhere in your organisation, a team is about to spend four months building a feature that will quietly die in production. Not because the engineering was bad. Because nobody built the infrastructure to find out it was the wrong bet before the cost became permanent.
The planning process looked rigorous. OKRs, design sprints, customer advisory calls. There was discipline, but the discipline was wrapped around educated guesses: research sessions capturing what customers say, which correlates loosely at best with what they do.
That gap between what a team believes and what production reveals is where most product investment goes to burn. Feature flag testing, done properly, is the only mechanism that closes it.
Not as a pre-release checkbox. As the backbone of a system that makes production experimentation safe, auditable, and repeatable—one that turns whether a feature will work or not from a matter of opinion into a matter of observation.
At its core, a feature flag is a mechanism for decoupling deployment from release—wrapping a new feature in a conditional so code ships to production without it being exposed to users. Straightforward enough at a small scale, but at enterprise scale, the challenge isn’t implementing the flags, it’s building the testing infrastructure around them so that production becomes a place where you learn, not just a place where you pray.
A real-world product learning loop, disguised as a cautionary tale
The McDonald’s AI drive-through story gets told as a punchline. The system spent a couple of years adding items customers didn’t order, misidentifying requests, generating exactly the sort of social media attention nobody at corporate wanted. They pulled it in June 2024 after running at hundreds of locations.
Look at it differently.
A major company built genuine real-world exposure. Accumulated signal across a significant sample of production traffic. Recognised the product wasn’t going to work at scale. Made a decision based on evidence rather than opinion.
That’s what a functioning product learning loop looks like. The system worked. The outcome just wasn’t the one they wanted and they had the data to know it, which is more than most organisations can say about features they shipped last quarter.
The problem is that the vast majority of businesses can’t absorb the same losses as McDonald’s during this testing phase. Most enterprise teams have never been able to run a real learning loop because the infrastructure to do it safely didn’t exist inside their organisation.
McDonald’s, which ran its AI trial between 2021 and 2024, continued to grow its quarterly revenue throughout. Most companies don’t have that margin for error, which is precisely why the testing infrastructure matters more than the ambition.
How feature flag testing closes the gap
AI coding tools have made this worse, not better. When writing code gets cheaper, the bottleneck shifts upstream—to the quality of the decision about what to build. Moving faster without better validation infrastructure just means arriving at the wrong place sooner.
The answer isn’t better beta testing. It isn’t more user interviews. It’s feature flag testing, operating as the foundation of a production experimentation system rather than a gate at the end of a development cycle.
Why traditional testing misses the point
Beta testing sounds like a learning mechanism. There’s a structural problem with it.
By the time a new feature reaches a beta cohort, the engineering investment is committed and the design is fixed. What development teams are collecting at that stage is their customers’ reactions to something that already exists, not observations of whether the feature changes how users actually behave. That’s a meaningful distinction, and it’s the one most teams blow past.
What’s actually needed is the ability to expose functionality to specific user segments in a production environment and watch what happens—without that exposure requiring a separate deployment or creating a compliance problem.
Testing strategy at the enterprise level has traditionally struggled to accommodate this. The tooling required to handle multiple flag states and different versions in production requires infrastructure most teams don’t have, so the instinct is to reach for automated testing frameworks. More test cases. A more complete test suite. Extending the test execution pipeline.
Unit tests and integration testing are necessary. They don’t answer the question of how real users respond to a new feature in a live production environment. That question lives in a different layer entirely, and no amount of additional testing overhead in a controlled environment resolves it.
The limitations of traditional testing aren’t a matter of rigour. They’re a matter of what kind of signal traditional testing is actually capable of generating.
The real blocker is governance, not code
Recognising those limitations is the easy part. The harder question is why most enterprise teams aren’t already running production experiments.
Ask a product team and the first answer is usually compliance. Ask the compliance team and they’ll describe an uncontrolled change with no authorisation trail, no segmentation documentation, no reversal mechanism, no audit record.
They’re not being obstructionist, they’re accurately describing what’s been put in front of them. Given that framing, caution is the right move.
The issue is that most experiment requests arrive without the governance infrastructure that would make approval defensible. Implementing feature flags properly changes that conversation.
Progressive rollout means new code reaches 1% of users before the entire user base sees it. A flag that disables a feature is a toggle rather than a redeployment. Approval workflows capture sign-off in the same system where the flag change is recorded, producing an automatic audit trail rather than a reconstructed one.
For regulated industries—financial services, healthcare, government—this is the difference between a proposal that requires trust and a configuration that can be reviewed against a framework other teams helped define.
Flag lifecycle management matters here, too.
Long-lived flags that outlive their original purpose don’t just sit there. They accumulate. And they interact. A dark forest of shadow architecture that engineers navigate by memory and tribal knowledge—until someone leaves, or an incident happens, and suddenly you’re spelunking through flags nobody can explain. Maintaining clear ownership of each flag, scheduling regular flag cleanup, and documenting a flag’s purpose as part of routine flag management aren’t bureaucratic overhead. They’re what keeps the forest navigable.
That governance foundation is the prerequisite. Once it’s in place, feature flag testing becomes a continuous feedback loop rather than a one-time exercise before launch.
What feature flag testing actually involves
With the governance infrastructure addressed, it’s worth being precise about what testing with feature flags covers. The topic spans several distinct scopes that behave differently.
Unit tests and code paths
The simplest part. Flags exist in code as conditional branches, so you can write test cases for each code path independently, regardless of which flag state triggers them. The flag’s purpose is to control which code blocks execute at runtime. That doesn’t change what unit tests do.
Test each path in isolation. Testing overhead here is minimal, whether you’re testing simple toggles or more complex flags with multiple variants.
Integration testing and handling multiple flag states
This is where complexity arrives and doesn’t leave.
When flags exist across a system, integration testing must account for how different flag states interact with one another. A naïve approach—testing every possible flag combination—quickly becomes unmanageable. Ten boolean flags produce 1,024 system states. Real enterprise products often have dozens of operational flags active simultaneously, making exhaustive combination testing impractical and the management of flag dependencies a genuine challenge for any automated testing framework.
What works instead: test the production state: the configuration real users will encounter. Test the all-off default state to ensure stability. Define user personas that represent meaningful segments, and write test cases around those personas rather than every permutation.
This is how you validate functionality without the test suite becoming unwieldy. End-to-end testing follows the same principle: cover the paths that matter for different user groups, not every theoretical system state.
Testing in production with real users
This is where feature flag testing delivers something no staging environment can.
When QA discovers unexpected behaviour in a feature that’s live under a flag, the blast radius is limited to the specific user segments that have been given access. Not the entire user base. No full rollback required. The flag is disabled, the affected segment is narrowed, and the issue is addressed before the feature is released more broadly.
This is what makes continuous delivery with feature flags genuinely different from traditional release management. Development teams can ship multiple versions of new code in a single day because each deployment into the production environment is insulated by flags. A deployment is not a release, and a release is not a commitment.
Deployment is separated from release, and quality assurance becomes an ongoing process—gathering feedback, monitoring performance, adjusting rollout—rather than a binary gate before launch.
According to the 2024 DORA State of DevOps report, elite-performing engineering teams—representing fewer than 20% of organisations surveyed—deploy multiple times per day and recover from failed deployments in under an hour.
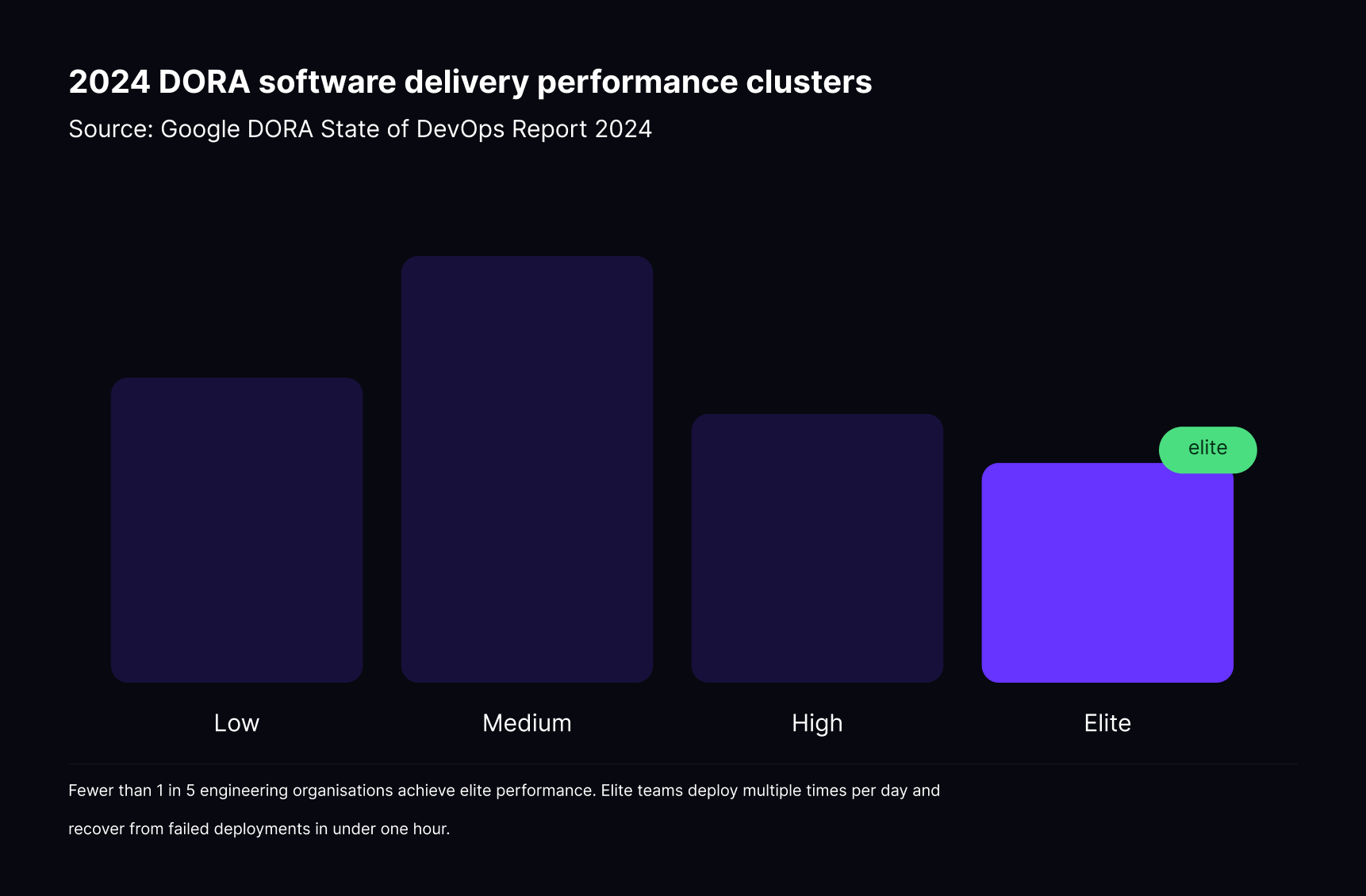
Feature flags are central to how those teams achieve that cadence, because the ability to release features to specific user groups rather than all users simultaneously removes much of the risk that forces lower-performing teams to deploy less frequently.
Feature flags and A/B testing: what’s the difference?
Understanding the mechanics of feature flag testing naturally leads to a question that often gets conflated: What’s the relationship between feature flags and A/B testing? It shouldn’t be.
Feature flags control who sees what. They’re the delivery mechanism; the infrastructure that routes users in different user segments to different versions of a feature.
A/B testing adds the measurement layer: you’re not just serving two variants to different user segments, you’re measuring which one produces the behaviour you want, using key metrics to make data-driven decisions.
When these are integrated in the same feature flag management tool, the loop closes: implement the flag, define the user targeting, ship the feature to a controlled percentage of users, measure the outcome, and make the call.
Without that integration, development teams end up with flags in one system and analytics in another. The signal gets lost between them, and the ability to make genuinely data-driven decisions from production behaviour depends on someone manually correlating two separate data sets. I’ve watched this happen. The data exists in both systems. The insight exists in neither.
A feature flag tool combined with A/B testing capabilities means measurement starts the moment you flip the flag. That’s not a convenience; it’s the difference between a production experiment and an anecdote. User segmentation and feature releases need to live in the same system for the feedback loop to close properly.
What good feature flag testing infrastructure looks like
Services for feature flag rollout and testing at the enterprise level need to cover more than simple on/off toggle functionality. Here’s what a well-structured setup actually requires:
Environment separation
Flags in development, staging, and production are independent. Testing teams can set their own rules in different environments without touching the production configuration, which allows the test suite to run against realistic flag states without risk to real users.
Progressive rollout
New flags go to a defined segment—for example, 1%, an internal team, or beta users—before any wider release. This phased rollout enables you to gather feedback from real users without exposing unexpected behaviour to your entire user base. The percentage adjusts without a new deployment.
Instant kill switch
Disabling a flag is a toggle, not a redeployment. In regulated industries, this is often a compliance requirement as much as an operational one: the ability to remove a feature immediately, without engineering intervention, needs to be available at all times. The 2 AM version of you will be grateful this exists.
Automatic audit trail
Every flag change, every approval, every rollout decision is logged automatically—captured at the time of the change, not reconstructed after the fact. The right governance infrastructure is what turns compliance from a blocker into a manageable process, and what makes feature flag testing sustainable at enterprise scale.
Approval workflows
Sign-off happens in the same system as the flag change. No side-channel email chains, no manual record-keeping. Other teams can review and approve changes against a documented, auditable process.
Integrated metrics
The ability to monitor performance against the key metrics that define whether a feature is achieving its goals, not just whether it deployed successfully. You need to know whether the thing is working, not just whether it’s running.
Choosing a feature flag tool with built-in testing support
Most feature flag tools handle the bare minimum competently at a small scale: boolean flags, basic user targeting, a simple dashboard. Enterprise development teams need more than that.
The governance layer—audit logs, approval workflows, role-based access control, environment isolation—needs to be built in from the start, not bolted on when the compliance team asks for it six months later, which is when you discover that a decision to add governance later was always a bet against your own growth.
The same applies to the experimentation layer. If A/B testing capability is separate from flag management, the signal gap between them becomes a permanent friction point. User targeting and the measurement of feature releases need to live in the same system.
For organisations in regulated industries, deployment options matter too.
A cloud-only tool creates a hard ceiling for data-sensitive teams. Self-hosted or private cloud options—with the full feature set intact—are often a requirement, not a preference. Many tools that look capable in a proof of concept reveal these limitations when it comes to managing features at production scale, in a real compliance environment, with multiple teams involved.
Here’s a table to help you decide when you need an enterprise-level feature flag testing solution:
The forest doesn’t get smaller
McDonald’s pulled the AI drive-through because they had enough data to know it wasn’t going to work. That’s not failure. That’s a system producing a signal and an organisation acting on it.
Most enterprise teams are still trying to get there—not because they lack ambition, but because they lack the infrastructure to run production experiments safely. The dark forest of unmanaged flags and ungoverned releases keeps growing, and the teams navigating it keep doing so by memory and instinct rather than instrumentation.
Feature flag testing, done properly, isn’t a development practice bolted onto the release process. It’s how you make the forest legible—how you turn every release into a hypothesis with a measurable outcome instead of a bet you can’t unwind.
The teams that win aren’t the ones that build fastest. They’re the ones who structurally eliminated the cost of being wrong, so speed stopped requiring courage.
See how Flagsmith’s controlled rollout and flag governance work in practice →
























OpenTelemetry, without the vendor lock-in: Introducing full observability for Open Source and Self-Hosted Flagsmith customers



































































.png)
.png)

.png)

.png)



.png)















.webp)