
Use feature flags to release code safely in any git branching strategy

Git has changed how software engineering teams work since 2008, mainly with the start of GitHub. Before a Distributed Version Control System (DVCS) like Git, CVS and SVN were the central VCS choices for development teams.
Git made it very easy to work with a branching workflow as it is easy, fast, and cheap to create branches in it. In this post, we will delve deeper into why smaller pull requests are super advantageous. We will also discuss how to use feature flags to contain the potential blast radius of any feature release.
Git branching models
There are at least three main git branching models. The first popular git branching model is Git-flow. A simpler version is the GitHub flow (or Simplified Git-flow), which has only one perpetual branch. The most simple but much more difficult to do practically is Trunk-based Development, where all the software engineers push to the main (master) branch. Let’s look at how these three git branching models work.
Git-flow
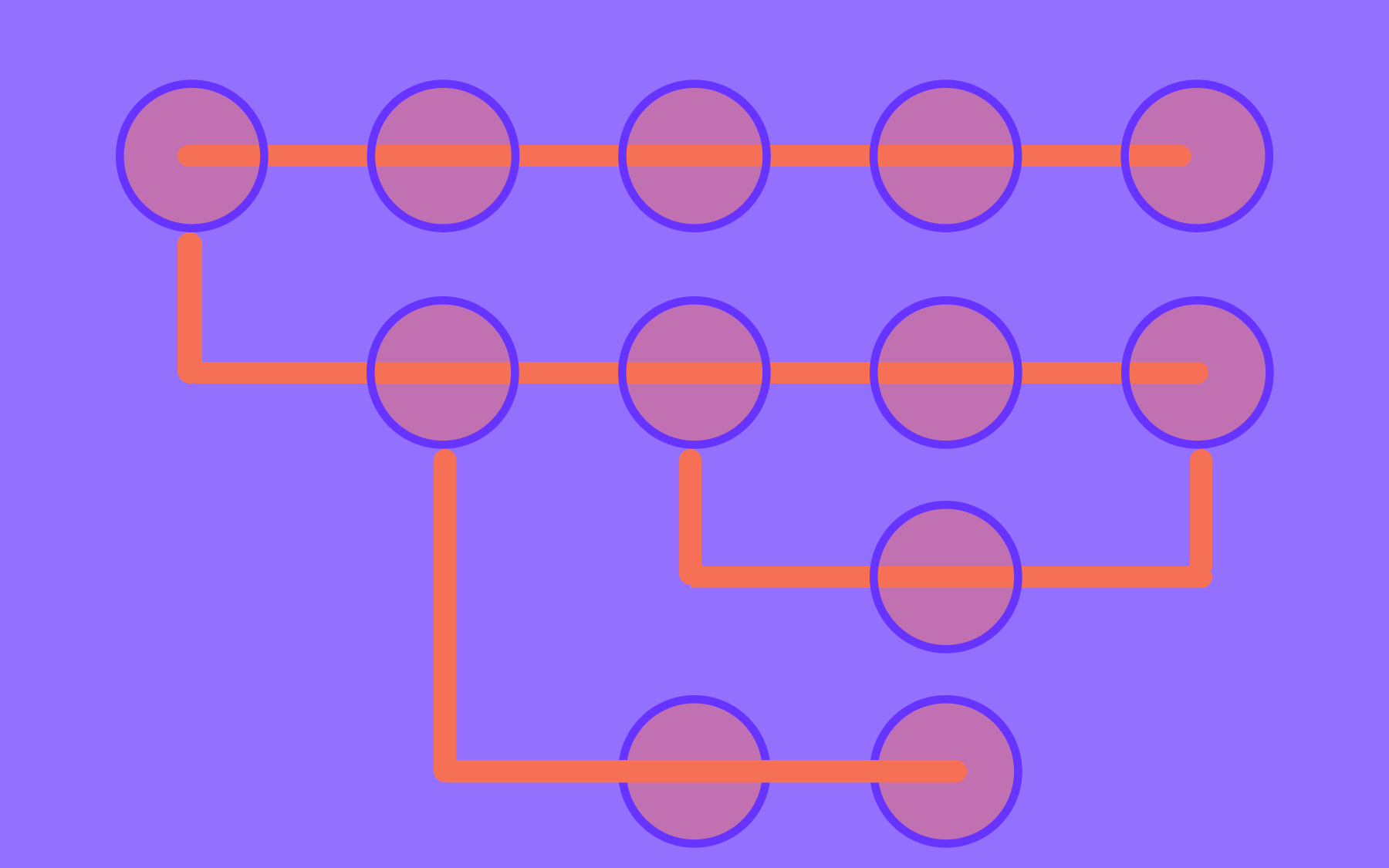
Git-flow has 3 perpetual branches, Master (main), Develop, and Release. Whenever a new software engineer wants to start work on a new task, they branch out the feature branch from the Develop branch. Pull requests are sent to the “Develop” branch. Multiple pull requests could be merged to Develop before deploying, and when it is time to release, a “Release” branch is created.
When the Release branch is stable it is merged back to Develop and Master. In case of an issue in the main branch, a hotfix branch is created and merged back to Develop and Master. You can find a more detailed explanation of this slightly convoluted process here. In summary, it looks like the below:

So, with little doubt, it is a long and difficult process to release software with Git-flow. It might be suited for projects with a scheduled release cycle but for normal projects, the overhead of 3 perpetual branches is a bit too much.
Feature flags can be used in this flow, primarily for canary deployments and A/B testing in the release phase. We will see how they can be even more valuable in the following models. Next up we will discuss, GitHub flow
GitHub Flow
In GitHub flow (Simplified Git-flow or Feature Branching Model), there is only one perpetual branch - Master (main). To start working on a new task the software engineer will take a new branch out from Master. They will do the commits, push the commits to run tests or any other CI builds on the new branch.
After that, when the work is done, the software engineer will open a pull request (or merge request) and get some feedback on the code. If the pull request is approved the software engineer will deploy the feature branch and when things are fine on production, merge the PR to the master (main) branch. Below is a quick summary:

GitHub flow is ultra-lightweight compared to Git-flow. It pushes for more regular deployments. As multiple pull requests are not stacked up one after the other, there are no issues of task A causing a side effect in task B. An additional benefit is that as the software engineer deploys the feature branch on production, feature flags can be utilized very well in this flow. This flow also avoids git merge conflict hell to a good extent. Long-running feature branches will surely invite merge conflict issues which can and should be mitigated with optimal use of feature flags.
Another aspect is the master (main) branch is always stable and can be deployed without risk anytime (unless someone has messed it up). GitHub flow is a good balance between not having too many perpetual branches or having just one branch for all software engineers which we will discuss next.
GitHub flow is complimented by feature flags really nicely. As mentioned above, feature flags can be used to mitigate the risks of long-running branches by allowing testing in production and reducing the blast radius of any potential issues. Feature flags are also well utilized in GitHub flow as they were with Git-flow for canary deployments, A/B testing, and more.
Trunk-based Development
Ever thought about what would happen if all the software engineers in a team push their code to the Master (main) branch? It is called Trunk-based development. You might think this is a crazy idea but it is not, it's being used by teams utilizing dependable automated tests, feature flags, and other techniques like pair programming where code is reviewed as soon as it is written. This model does not brush off the idea of code reviews. Like shift-left security reviews are moved to the code writing phase. In other models, the software engineer writes the code, commits and pushes the code, then opens a pull request which paves way for someone to review the code changes async.
Digging in a bit deeper, practical Trunk-based Development is a requirement for pure Continuous Integration (CI). Simply put, there is only one branch and everyone pushes to that branch - Master. This means the tests cannot fail, if they do you are breaking code and flow for the whole team.

There is a concept of the short-lived branches, but that path makes it more like a GitHub flow model. How pure you want to be on this is up to you.
Following this workflow is a mindset shift where each software engineer needs to be extra careful to not break the builds. On top of that, they need to write code in small, testable, and independent parts that can be deployed to production anytime without any issues. Please do spend 5 minutes reading this interesting overview.
This model gets the most value from feature flags of any. In fact, to say that feature flags are a prerequisite for Trunk-based Development is not wrong. They are used to all of their potential, and along with most if not all releases in this model. We will explain this in more depth later in the article. This is a true testament that deployment is not release, as a software engineer needs to be super iterative and ultra-careful because there is only one branch to work with. This takes us to our next point, why smaller batches are advantageous.
Advantages of smaller changes
Ask yourself a question, would you be happy and comfortable to do a code review on code changes of 2 lines on a single file or 700 lines spread across 50 files. Without a doubt, the first one. As the change is small it is easier to comprehend, and given the blast radius is so small the risk for deployment and release is almost non-existent.
Compare this to the 700 liner change needing code review; it cannot be finished in a single sitting and would be best done sync rather than fully async. A study by Smart bear says: a review of 200-400 LOC over 60 to 90 minutes should yield 70-90% defect discovery. That is good but not great, so the 700 liner code review if not done properly is a pretty big risk.
In addition to having lesser defects, smaller pull requests have the following advantages too:
- It reduces cycle time
- It accelerates feedback
- Small changes are reviewed faster which increases efficiency
- Smaller pull requests are low risk
An open pull request (PR) is a liability in at least 2 ways. First, it's a feature/fix not shipped to customers. Second, it will invite code conflicts soon.
GitHub’s 2020 productivity report says: “Throughout the year, developers stepped up their work by keeping pull requests at the same size or smaller and merged pull requests up to seven and a half hours faster. This gives developers more time to do the things they love.”
It also adds: “Teams can develop more effectively and efficiently by creating smaller pull requests and automating the development workflow. This allows you to collaborate more efficiently, conduct better code reviews, and reduce manual work so you can ship code faster.” So if smaller pull requests have so many upsides, how can we make our pull requests smaller? One of the sure-shot ways is by using feature flags and remote config.
Use feature flags to keep pull requests small and release features gradually
Even if there is a small feature to develop, it is advisable to have multiple pull requests to get it working rather than a huge pull request that has all the changes in one go. If these changes are some new files or classes with proper unit tests, it is much easier to open pull requests with these isolated files. As soon as the glue code is in place and these new files or even functions are accessible from the user interface, the best way to make them accessible but gated with conditions is by using feature flags.
Feature flags can be implemented in multiple ways, a simple `if` statement can be a poor man’s feature flag, and depending on the need a full-on SAAS or self-hosted product like Flagsmith can be used. Flagsmith has both cloud and self hosted offerings. In addition to that, Flagsmith being open source is a great feature.
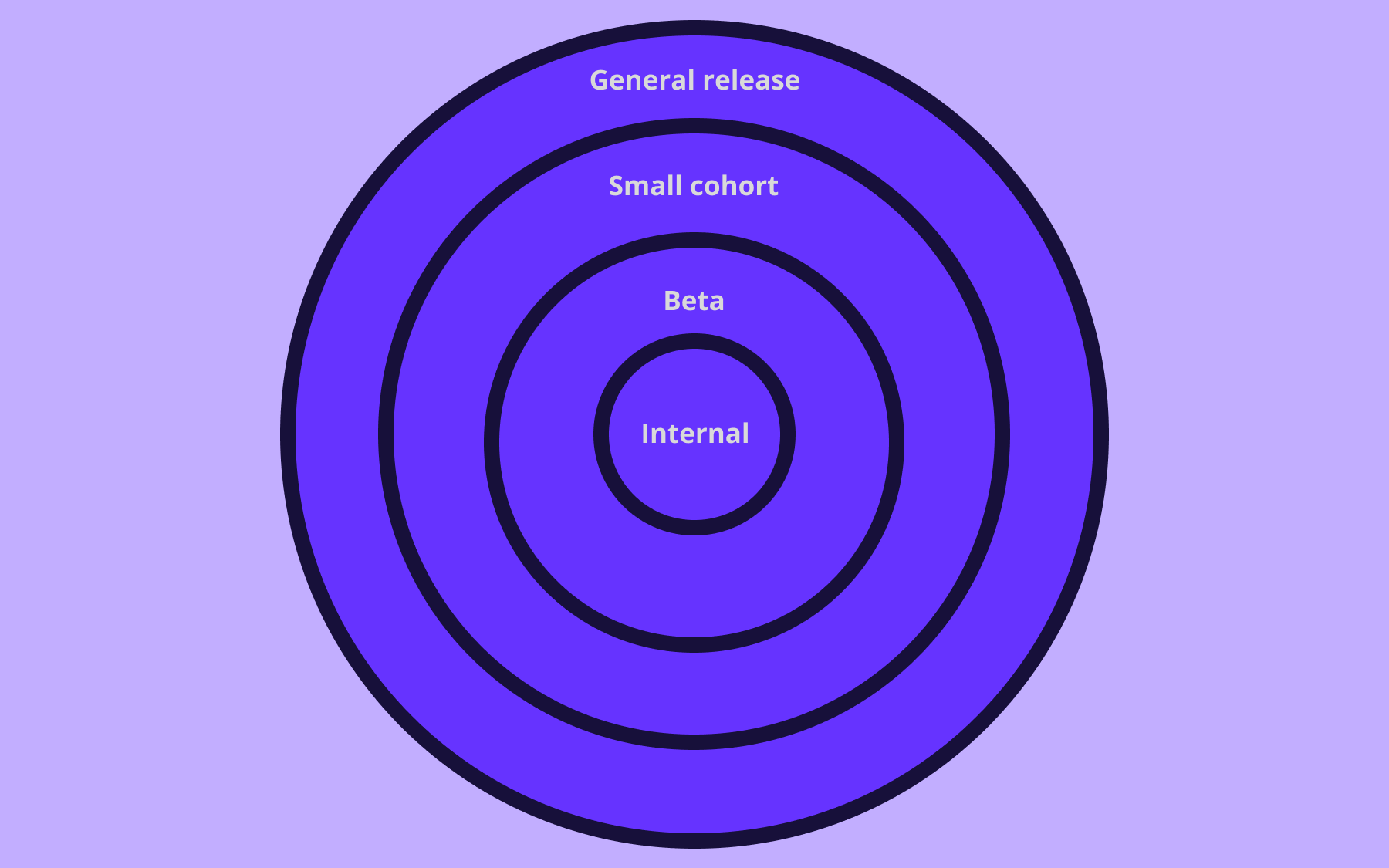
With a proper mix of small pull requests and feature flags, even large features can be released gradually step by step. An incremental way to release can be that after the feature is deployed and available on production, it is released via feature flag to only the software engineer who developed it. That way they can test it on production first.
Following this canary deployment approach, as a next step, the particular team responsible for that feature can be added to the feature flag. After having some confidence in the code, the whole organization can be part of the feature flag. Slowly it can be released to 1% of the customer base, which can be increased to 5% in a week’s time. All along this path, as soon as a bug or edge case is discovered it can be fixed.
Keep in mind the blast radius of the bug is 1 person at the beginning and if the organization is 200 people it is just those 200 people, not the thousands or millions of customers using the software. With Flagsmith integrations like Datadog, New Relic and the likes, it's easy to find out if there is any issue in the newly introduced feature with reliable monitoring and alerting. Companies like GitHub and Palo Alto use feature flags to deploy code safely, it should be a no-brainer for companies and software engineering teams like ours to exploit them.
Other techniques to keep pull requests small
Feature flags are surely a great way to keep pull requests small and leverage all its advantages. There are other techniques as well that enable creating smaller changes that are low risk and aid high productivity. One of these techniques is enabler code last. For instance in most web applications as long as the code is not wired up with a route (URI via a controller) it cannot be reached from outside by the customers. If the software engineers can open multiple pull requests with high test code coverage to other parts except for the route (or controller) these code segments can be deployed but they will never be “released” or executed even though available.
Another non-technical but highly effective technique is to discuss first and code next. Many times if you discuss your approach to solve a problem with an engineer senior to you they might have a different take on the solution and how to approach it. Most often than not, engineers senior to me have always given me paths on how to break the task and its pull request into smaller chunks so that work moves ahead much faster and the risk is largely mitigated too. Never underestimate the power of smaller pull requests and the different techniques to achieve it.
Conclusion
Regardless of which Git branching model our teams follow, smaller changes (or pull requests) are key to releasing software safely and having a high level of productivity. With a mix of feature flags and other techniques we can release software safely to our valued customers once it is tested step by step in multiple iterations by the team and the whole organization on production. Use the right mix of smaller pull requests and feature flags to reach software release zen.


























OpenTelemetry, without the vendor lock-in: Introducing full observability for Open Source and Self-Hosted Flagsmith customers




































































.png)
.png)

.png)

.png)



.png)











.webp)